Test Failure Analysis: 10 Reasons Why Software Tests Fail
Learn why software tests fail and how test failure analysis helps you fix flaky tests, stabilize CI/CD pipelines, reduce defect leakage, and ship reliable releases.

A red build notification minutes before release is something every engineering team has experienced, yet not every team knows how to respond strategically.
This is where Test failure analysis becomes more than debugging; it becomes a core practice in modern software testing and quality assurance.
When software tests fail, the root cause could be flaky tests, unstable test data, environment configuration mismatches, or genuine software defects hidden deep in the codebase.
Without structured test failure analysis, teams risk delayed release cycles, increased defect leakage, and unreliable test automation pipelines.
In this guide, you will learn how to approach Test failure analysis systematically, understand the most common reasons for software test failures, and apply proven strategies to improve test reliability, reduce costs, and strengthen overall software quality.
What is a test failure?
A test failure occurs when the actual outcome of a test case does not match the expected result defined during test design.
In software testing and test automation, this indicates that the system under test behaved differently than anticipated under specific conditions.
Test failures can arise from genuine software defects, incorrect test assertions, unstable test data, or environment configuration mismatches. Identifying whether the failure is caused by a real bug or by issues within the test itself is the first step in effective Test failure analysis.
In modern CI/CD pipelines, failed test cases immediately signal potential risks to software quality and release stability.
Without proper test failure analysis, teams may struggle with flaky tests, delayed release cycles, and unreliable automated testing processes.
What is test failure analysis?
Test failure analysis is the systematic process of investigating failed test cases to identify their root causes and determine appropriate corrective actions.
It goes beyond simply noticing that a software test failed and focuses on understanding whether the issue stems from a genuine software defect, flaky tests, unstable test data, timing problems, or environment configuration mismatches.
In modern software testing environments, especially within CI/CD pipelines like GitHub Actions or Jenkins, test failure analysis plays a critical role in maintaining reliable test automation.
Instead of rerunning failed test cases blindly, teams analyze technical evidence to classify failures accurately and prevent recurring instability.
A structured test failure analysis process typically includes reviewing:
-
Execution logs
-
Stack traces
-
Screenshots and trace files
-
Network activity logs
-
Test observability dashboards
-
Environment configuration details
Effective Test failure analysis transforms failed test data into actionable insights, improving test reliability, reducing defect leakage, and strengthening overall software quality assurance practices.
Why is test failure analysis important?
Ignoring failed test cases may seem minor at first, but over time, it leads to defect leakage, unstable releases, and growing technical debt across the software testing lifecycle.
Strong Test failure analysis practices reduce mean time to resolution (MTTR), improve automated test reliability, and reinforce consistent software quality assurance standards.
1. Impact on Software Quality
When teams implement systematic Test failure analysis, they detect functional and integration defects before they reach production. This directly improves software reliability, strengthens system stability, and enhances overall user experience.
Key impacts on software quality include:
-
Early identification of application defects
-
Reduced defect leakage during regression testing Higher confidence in automated test coverage
-
Elimination of flaky tests and unstable test scripts
-
Stronger alignment between expected and actual behavior
Consistent failure investigation ensures that automated testing reflects real-world application behavior and supports long-term quality improvement.
2. Cost of Late Defect Detection
Defects discovered in production environments are significantly more expensive to fix than those identified during earlier testing phases. Effective Test failure analysis reduces operational costs by enabling early debugging, structured root cause analysis, and preventive action.
Major cost-related advantages include:
-
Reduced rework and refactoring effort
-
Fewer urgent hotfix deployments
-
Lower downtime-related financial impact
-
Decreased customer support escalation
-
More efficient allocation of development resources
By strengthening test failure analysis processes, organizations minimize financial risks and maintain development efficiency.
3. Influence on Release Cycles
Unresolved flaky tests, environment configuration mismatches, and unstable automation pipelines can slow down release timelines and create uncertainty in deployments. Through disciplined Test failure analysis, teams remove instability and maintain smooth, reliable CI/CD workflows.
Release cycle improvements include:
-
Faster root cause identification
-
Reduced pipeline interruptions
-
Improved regression suite consistency
-
Greater deployment confidence
-
Shorter feedback loops for developers
High-performing engineering teams treat every failed test case as a quality signal, ensuring that test failure analysis remains a proactive and strategic part of software delivery.
What are the benefits of test failure analysis?
Test failure analysis delivers measurable ROI by improving engineering efficiency and strengthening overall software quality assurance.
By systematically investigating failed test cases, teams enhance automated testing reliability and build more stable CI/CD pipelines.
1. Faster Debugging and Resolution
Structured test failure analysis reduces guesswork by relying on execution logs, stack traces, and observability artifacts to identify root causes quickly. This approach shortens debugging cycles and improves mean time to resolution (MTTR).
-
Reduced time spent rerunning failed test cases
-
Clear separation of flaky tests from genuine software defects
-
Faster stabilization of regression suites
-
Improved CI/CD pipeline reliability
-
Better visibility into synchronization and timing issues
2. Improved Test Reliability
Consistent test failure analysis helps eliminate flaky tests and unstable test scripts that weaken automation trust. Reliable automated testing increases confidence in regression results and strengthens overall software testing accuracy.
-
Reduced intermittent software test failures
-
Higher confidence in CI results
-
Improved test coverage validation
-
Stronger alignment between test cases and business requirements
-
More dependable automated testing outcomes
3. Better Resource Allocation
Effective failure categorization allows teams to prioritize high-impact defects instead of spending time on low-risk or repetitive issues. This improves sprint planning, defect management, and engineering productivity.
-
Clear prioritization of critical path failures
-
Reduced redundant debugging efforts
-
Better collaboration between QA and development teams
-
More efficient use of engineering resources
-
Improved focus on high-severity software defects
4. Enhanced Product Stability
By identifying recurring failure patterns, test failure analysis strengthens system robustness and prevents similar issues from resurfacing. Over time, this leads to lower defect leakage rates and more predictable release cycles.
-
Fewer production incidents
-
Reduced regression instability
-
Stronger CI/CD workflow consistency
-
Increased release confidence
-
Improved long-term software reliability
Types of test failures
Understanding different failure categories improves diagnostic accuracy and strengthens Test failure analysis workflows.
Each type of software test failure requires a distinct debugging strategy to maintain reliable automated testing and stable CI/CD pipelines.
| Failure Type | Typical Symptoms | Primary Owner | Debug Strategy |
|---|---|---|---|
| Flaky | • Passes/fails randomly • Timing issues • Race conditions |
QA + Dev | • Isolate & retry • Check waits/timeouts • Review failure logs |
| Consistent | • Fails every run • Reproducible error • Same stack trace |
Dev Team | • Check recent changes • Verify assertions • Debug locally |
| New | • Fails after code/env change • Feature-related • Baseline mismatch |
Dev (Author) | • Compare with baseline • Review recent commits • Verify test setup |
| Performance | • Slow execution • Timeouts • Resource-heavy |
Dev + DevOps | • Profile performance • Check resources • Optimize queries/waits |
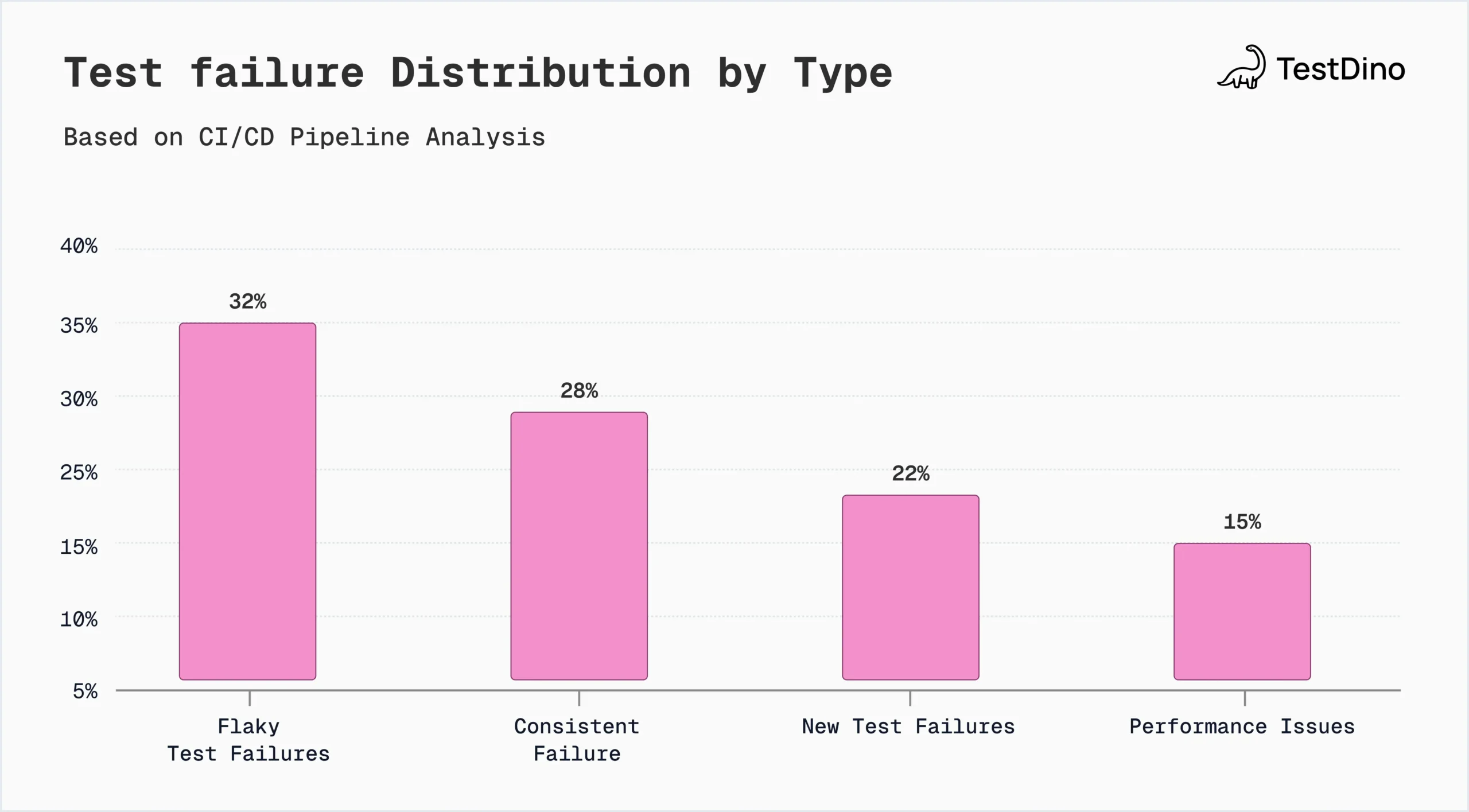
1. Flaky Test Failures
Flaky tests pass and fail intermittently without any changes to the underlying codebase, making them one of the most frustrating issues in test automation.
These failures are commonly caused by timing issues, race conditions, unstable test data, environment configuration mismatches, or network latency.
To reduce flaky test failures, teams should:
-
Implement proper synchronization and wait strategies
-
Avoid hard-coded delays in test scripts
-
Isolate test data and eliminate shared state
-
Stabilize external dependencies through mocking
-
Monitor parallel execution conflicts
Eliminating flaky tests is critical for improving automated test reliability and increasing confidence in regression testing results.
2. Consistent Test Failures
Consistent test failures occur repeatedly under identical conditions and are typically easier to reproduce.
These failures often indicate genuine software defects, incorrect test assertions, or outdated business logic validations.
Common causes include:
-
Real application bugs in new or existing features
-
Incorrect expected values in test assertions
-
Broken API integrations
-
Invalid or outdated test data
-
Configuration mismatches between environments
In Test failure analysis, consistent failures are usually prioritized because they represent deterministic issues that directly impact software quality and product functionality.
3. New Test Failures
New test failures appear after code refactoring, feature implementation, dependency updates, or infrastructure changes. Regression testing plays a key role in identifying these failures before deployment.
Typical triggers include:
-
Recent code changes affecting shared components
-
Updates to third-party libraries or APIs
-
Modifications in the database schema
-
Changes in environment variables or configurations
-
UI changes that break existing selectors
Structured root cause analysis ensures that new test failures are quickly categorized as either expected behavior changes or unintended regressions.
4. Performance-Related Failures
Performance-related failures occur when system responsiveness degrades beyond acceptable thresholds. These failures may surface as timeouts, slow API responses, memory leaks, or resource contention during automated test execution.
Common performance-related causes include:
-
Increased CPU or memory usage
-
Database query inefficiencies
-
Network bottlenecks
-
Improper caching configurations
-
Scalability limitations under load
Monitoring system metrics such as CPU usage, memory consumption, and API latency helps diagnose performance anomalies and strengthens proactive test failure analysis practices.
By understanding these test failure categories, teams improve debugging efficiency, reduce recurring instability, and maintain high standards in software testing and quality assurance.
10 common reasons for test failures
Understanding the root causes behind software test failures is essential for performing effective Test failure analysis and improving automated testing reliability.
Below are the most common reasons explained in a clear and practical way to help engineering and QA teams diagnose failures faster.
1. Incorrect Test Assertions
When test assertions do not reflect the current business logic or expected behavior, they produce false failures that confuse teams. Even small mismatches between expected and actual results can lead to misleading regression outcomes.
-
Assertions are written based on outdated feature requirements that have since changed.
-
Expected values are hardcoded and not updated after UI or API modifications.
-
Validation logic does not properly handle edge cases or optional fields.
-
Negative test cases are incorrectly structured, causing false negatives.
-
Assertions check UI text or attributes that are dynamically generated and inconsistent.
2. Software Defects or Bugs
Genuine application defects are one of the most direct causes of failed test cases. These failures usually signal functional breakdowns that require immediate debugging and resolution.
-
Incorrect business logic implementation leading to wrong outputs.
-
API endpoints are returning incorrect status codes or malformed responses.
-
Database constraints or schema mismatches are causing transaction errors.
-
Broken integrations between microservices.
-
Recently introduced features conflict with existing functionality.
3. Flaky or Unstable Test Scripts
Flaky tests are intermittent and unpredictable, which makes them especially harmful to automation trust. They reduce confidence in CI/CD pipelines and increase unnecessary debugging time.
-
Missing or improper wait strategies are causing race conditions.
-
Use of unstable or overly complex element selectors.
-
Dependence on real-time data or external services without proper isolation.
-
Parallel test execution is interfering with shared resources.
-
Inconsistent handling of asynchronous UI updates or API responses.
4. Unstable or Outdated Test Data
Test data plays a critical role in automated testing, and unstable datasets can lead to inconsistent failures. Without controlled data management, regression testing becomes unreliable.
-
Expired authentication credentials or session tokens.
-
Missing mandatory input values in datasets.
-
Data collisions caused by shared databases across parallel tests.
-
Lack of cleanup processes after test execution.
-
Hardcoded test data that no longer aligns with system updates.
5. Environment Configuration Mismatches
Inconsistent environments between development, staging, and production frequently cause unexpected behavior. Even minor configuration differences can lead to repeated software test failures.
-
Different browser versions produce varied rendering behavior.
-
Mismatched dependency versions between local and CI environments.
-
Missing environment variables required for application startup.
-
Inconsistent database connection strings.
-
Time zone or localization differences affecting test outputs.
6. Changes in Dependencies or Third-Party Services
Modern applications rely heavily on external APIs and libraries, which can introduce instability when updated. Without proper version control and mocking strategies, these changes can break stable automation suites.
-
API contract modifications that alter response formats.
-
Deprecated methods in updated third-party libraries.
-
Temporary outages in payment gateways or authentication services.
-
Version conflicts between framework updates and plugins.
-
Security patches changing request validation rules.
7. Timing and Synchronization Issues
Asynchronous operations in modern web and mobile applications can cause premature assertions if not handled properly. Proper synchronization is essential for accurate automated testing.
-
UI elements load after the test attempts interaction.
-
Delayed background API calls are not fully completed.
-
Insufficient timeout configurations.
-
Animation or transition delays are interfering with UI validation.
-
Improper handling of dynamic content rendering.
8. Inadequate Test Coverage
Insufficient regression coverage often allows hidden defects to surface later in the release cycle. Comprehensive testing ensures that both standard and edge-case scenarios are validated.
-
Critical user workflows are not included in automation suites.
-
Edge cases and boundary values were not tested thoroughly.
-
Lack of integration tests across dependent modules.
-
Missing negative testing scenarios.
-
Failure to update test coverage after feature additions.
9. Parallel Execution Conflicts
Running multiple tests simultaneously improves speed but can introduce data and resource conflicts. Without isolation strategies, concurrency leads to unstable outcomes.
-
Shared user accounts are causing authentication conflicts.
-
Simultaneous database writes create record collisions.
-
Session reuse across tests is causing unexpected behavior.
-
Competing background processes are consuming shared system resources.
-
Improper cleanup between test runs affects subsequent executions.
10. Poor Test Maintenance and Refactoring
Test automation is not a one-time effort and requires continuous updates as the application evolves. Neglected test scripts gradually become unreliable and generate frequent failures.
-
Outdated UI selectors after frontend redesigns.
-
Deprecated framework methods not replaced in scripts.
-
Hardcoded configurations are not updated after infrastructure changes.
-
Duplicate or redundant test cases increase maintenance complexity.
-
Lack of regular review and optimization of regression suites.
By understanding these detailed causes, teams strengthen Test failure analysis, improve regression stability, and ensure that automated testing continues to support high software quality standards rather than slow down development processes.
Who needs to analyze test failures?
Test failure analysis is not limited to a single role in the software development lifecycle but is a shared responsibility across agile and DevOps teams.
Each stakeholder contributes unique technical or business insight to ensure failed test cases are properly investigated and resolved.
1. Developers
Developers play a central role in analyzing failed test cases because they understand the application architecture, logic flows, and system dependencies. Their technical expertise helps determine whether a failure is caused by a genuine software defect, integration issue, or incorrect implementation.
-
Debug failing assertions and review stack traces to identify code-level defects.
-
Analyze recent commits to determine whether new changes introduced regressions.
-
Fix logic errors, API contract mismatches, or data validation issues.
-
Refactor unstable components to prevent recurring software test failures.
-
Improve code quality through better exception handling and validation logic.
By actively participating in Test failure analysis, developers reduce defect leakage and improve long-term system stability.
2. QA Engineers
QA engineers are responsible for maintaining the integrity and reliability of the test automation framework. They ensure that failed test cases are correctly categorized and that flaky tests are identified before affecting CI/CD pipelines.
-
Validate whether failures are caused by incorrect test logic or actual defects.
-
Maintain regression suites and update test cases after feature changes.
-
Monitor flaky test ratios and remove unstable automation scripts.
-
Improve synchronization strategies to reduce timing-related failures.
-
Ensure proper test data management and environment consistency.
Through structured failure investigation, QA engineers strengthen automated testing reliability and maintain high software quality assurance standards.
3. Product Managers
Product managers evaluate test failures from a business impact perspective. Their role ensures that defect prioritization aligns with customer expectations and release goals.
-
Assess the severity and business risk of reported failures.
-
Prioritize defect resolution based on feature importance and user impact.
-
Balance quality improvements with release timelines and delivery goals.
-
Communicate failure risks to stakeholders and leadership teams.
-
Make informed decisions about hotfixes versus scheduled releases.
Their involvement ensures that Test failure analysis supports strategic product planning rather than just technical debugging.
4. Business Analysts
Business analysts ensure that failed test cases are evaluated against documented requirements and acceptance criteria. They help confirm whether the failure represents a real deviation from business expectations.
-
Verify that functional requirements are correctly implemented.
-
Review acceptance criteria for accuracy and completeness.
-
Clarify requirement ambiguities that may cause incorrect test assertions.
-
Validate edge-case scenarios affecting user workflows.
-
Ensure alignment between development output and business objectives.
By contributing requirement-level insights, business analysts help ensure that software test failures are resolved accurately and that the final product meets both technical and business expectations.
How test failure analysis supports defect management
Strong Test failure analysis directly strengthens structured defect management processes by ensuring every failed test case is investigated, categorized, and documented accurately.
It improves traceability, prioritization, and long-term defect prevention across the software development lifecycle.
1. Defect Detection and Reporting
-
Automated test failures trigger issue creation in tools like Jira or Azure DevOps.
-
Execution logs, screenshots, and trace artifacts are attached for better context.
-
Each defect is linked to specific builds, commits, and regression test cases.
-
Failure history is tracked across releases for better trend analysis.
-
Clear documentation reduces miscommunication between QA and development teams.
2. Root Cause Prevention
-
Recurring flaky tests are identified and permanently stabilized.
-
Repeated configuration mismatches are standardized across environments.
-
Frequently failing modules are prioritized for refactoring.
-
Root causes are documented in internal knowledge bases.
-
Preventive guidelines are created to reduce future regression risks.
3. Prioritization and Verification
-
Critical path failures are resolved before low-impact issues.
-
High-severity defects are escalated based on business risk.
-
Regression failures are validated against acceptance criteria.
-
Fixes are verified through structured retesting.
-
Release readiness is confirmed only after all major failures are cleared.
By aligning structured investigation with reporting, prevention, and prioritization, Test failure analysis becomes a central pillar of effective defect management and long-term software quality assurance.
Best practices for test failure analysis
Applying structured Test failure analysis best practices improves automated testing reliability and strengthens software quality assurance. The table below summarizes key practices with short and clear explanations.
| Best Practice | Why It Is Important |
|---|---|
| Categorize failures immediately | Helps quickly separate real defects from flaky tests or environment issues. |
| Maintain deterministic test design | Reduces intermittent failures caused by poor synchronization. |
| Standardize test environments | Prevents failures due to configuration mismatches. |
| Use version-controlled test data | Ensures consistent and repeatable test execution. |
| Monitor failure trends | Identifies recurring issues early. |
| Isolate tests in parallel execution | Prevents shared resource conflicts. |
| Store detailed failure artifacts | Speeds up debugging and root cause analysis. |
| Refactor test suites regularly | Keeps automation stable as the application evolves. |
| Integrate analysis into CI/CD | Ensures failures are resolved before deployment. |
| Document root causes | Prevents repeated defects and improves team knowledge. |
Conclusion
Test failures are not obstacles but valuable signals that highlight gaps in code quality, test design, environment configuration, or test data management. With structured Test failure analysis, teams can transform failed test cases into actionable insights that improve automated testing reliability and strengthen software quality assurance.
By consistently identifying root causes and eliminating flaky tests, organizations reduce defect leakage and stabilize CI/CD pipelines. Over time, disciplined test failure analysis leads to faster releases, lower operational costs, and more resilient, high-quality software.
FAQs

Dhruv Rai
Product & Growth Engineer



