

AI Agent Testing: From Hype to Production
AI agent testing splits into four workflows: generation, maintenance, triage, and exploration. Here's which ones ship and which stay in demos.






Every post you've read on "AI agent testing" treats agents as a single idea.
They aren't.
In a real Playwright pipeline, AI agent testing splits into four distinct workflows. Each uses different tools. Each fails for different reasons. Each needs different data to work at all.
Some workflows are production-ready today. Others are demos with confident voice-overs. A lot of what people call "AI agent testing" is actually four very different things wearing the same label, and the 2025 research literature has started to sort out which ones work.
By the end, you'll have a mental model sharp enough to pick the one category to adopt this sprint and the guardrail to ship with it.
What is AI agent testing?
The agents we're covering here do QA work on your software: writing Playwright tests, fixing broken selectors, classifying CI failures, and clicking around staging environments. They don't test themselves. They test your code.
Most blogs open with a taxonomy from a university AI textbook: simple reflex, model-based, goal-based, utility, and learning. That chart is fine for a CS class. It tells you nothing about which tool to run on Monday, so we're skipping it.
The taxonomy that actually predicts outcomes is the one that groups agents by the job they do, and Playwright's own documentation increasingly organizes around that split. If you want a refresher on the syntax the agent is generating, Playwright's writing tests guide is the reference.
The 4 categories that actually matter
Here's the map you can tape to your monitor.
Each category addresses a specific pain point, uses specific tools, and lives at a specific point in your CI pipeline. Mixing them up is why "we tried AI testing" conversations end in disappointment.
The four categories:
- Generation agents write new tests. Claude Code, Cursor, and Copilot writing Playwright tests from specs, user stories, or existing page objects. These live in your IDE.
- Maintenance agents fix existing tests. Broken selectors after a UI refactor, stale assertions, deprecated API calls. They live in a pre-commit or nightly job.
- Triage agents explain CI failures. Grouping similar errors, classifying bug vs flaky vs environment, writing an investigation brief. They live on top of your test failure analysis layer.
- Exploration agents click around autonomously. Stagehand, browser-use, Auto-playwright, Operator-style agents. Given a login and a goal, they click through your app and report what broke. These live in a nightly exploratory job, not your PR pipeline.

Tip: Map your current sharpest pain to exactly one of these four before you evaluate any tool. A generation agent will not fix a flaky suite. A triage agent will not write new coverage.
See how the four agent categories interact with the data layer that powers them:
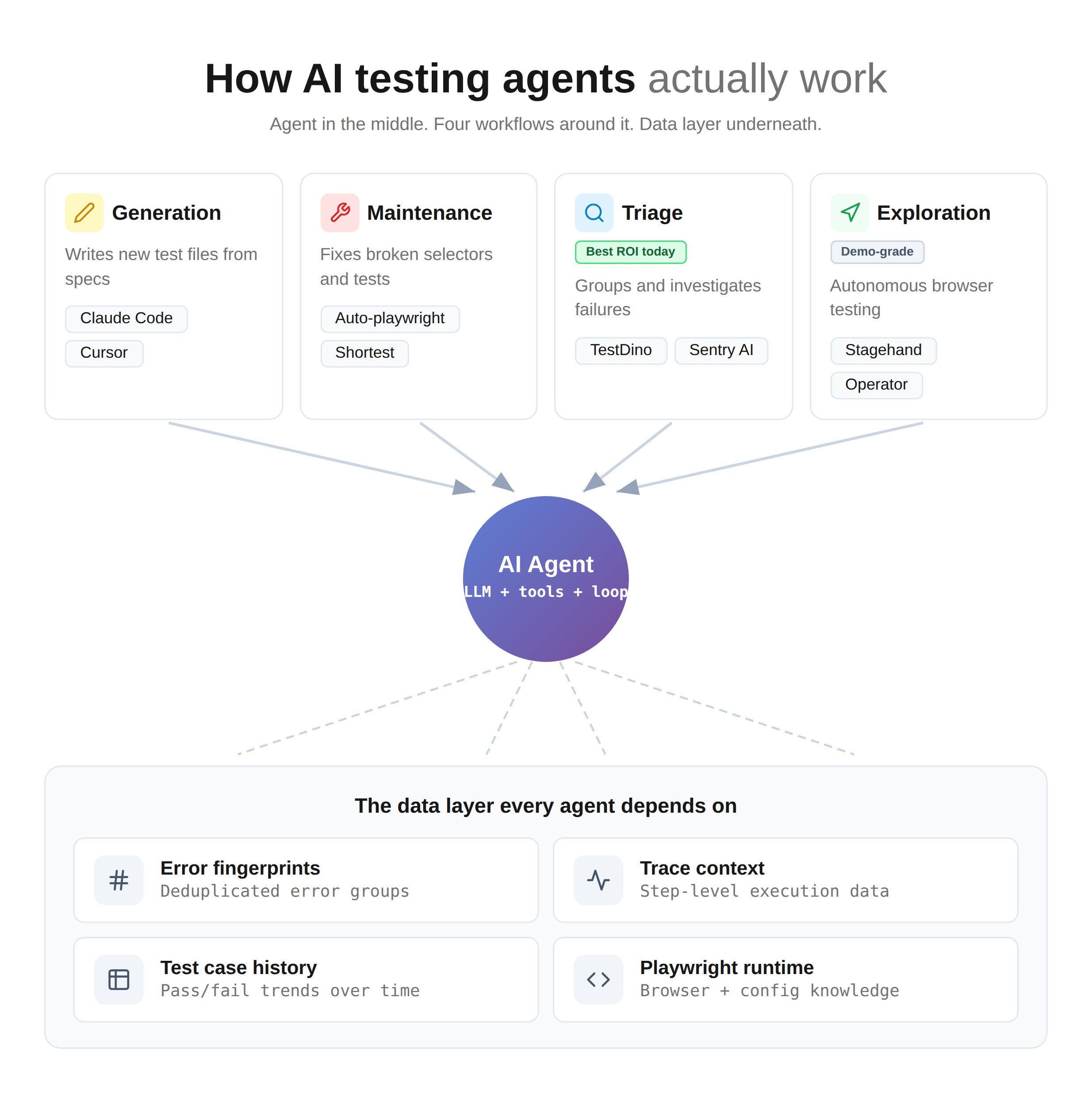
Where each category plugs into your pipeline
| Category | Canonical tools | Primary input | Primary output | Lives in | Maturity (April 2026) |
|---|---|---|---|---|---|
| Generation | Claude Code, Cursor, Copilot, AI test generation tools | Spec, user story, page object | Playwright .spec.ts file | IDE, PR draft | Promising with guardrails |
| Maintenance | Auto-playwright, Shortest, custom LLM scripts | UI diff, broken test output | Patch PR | Pre-commit, nightly | Fragile without review |
| Triage | TestDino, Sentry AI, custom LLMs | Grouped errors, trace, test history | Investigation brief, labels | Post-CI run | Ready today |
| Exploration | Stagehand, browser-use, Auto-playwright | Login, high-level goal, URL | Bug report, session trace | Nightly exploratory | Demo-grade |
Playwright 1.59: The runtime caught up to the agent use case
The Playwright 1.59 release shipped four features built specifically for agent workflows, which is worth noting because 1.59 maps almost one-to-one onto the categories above.
browser.bind() lets a launched browser accept connections from playwright-cli, @playwright/mcp, and other clients at the same time. A generation agent can now write a test while a triage agent inspects the same session. Multi-agent setups finally have a native runtime.
The new page.screencast API includes what the Playwright team calls "agentic video receipts": coding agents can record a walkthrough video with chapter titles and action annotations after completing a task, giving human reviewers a faster signal than reading log output. For generation-agent review workflows, this is substantial.
npx playwright test --debug=cli lets a coding agent attach and step through a test interactively, and npx playwright trace exposes trace analysis from the command line so agents can reason about failures without loading a GUI. Both reduce the gap between "LLM wrote some code" and "LLM can tell whether the code works."
Note: If your agent stack was built against Playwright 1.55 or earlier, upgrading to 1.59 is the single highest-impact change you can make in Q2. The primitives are finally there.
What works in generation and maintenance
One rule covers both: generation + filter, never generation alone.
Generation: The Meta evidence
The best industrial data on LLM test generation comes from Meta. In Mutation-Guided LLM-based Test Generation at Meta (Alshahwan et al., FSE 2025 Industry Track), the team shipped their ACH system to Messenger and WhatsApp test-a-thons.
Engineers accepted 73% of the LLM-generated tests. 36% were judged privacy-relevant.
The number everyone quotes is 73%. The number nobody quotes is how they got there.
ACH doesn't just ask an LLM to write tests. It runs a mutation-guided loop. Mutants of the code under test get generated. The LLM writes tests designed to kill those mutants. A second LLM agent acts as an equivalent-mutant detector with 0.79 precision and 0.47 recall at baseline, rising to 0.95 and 0.96 after pre-processing.
In other words, the filter matters more than the generator.
Warning: Any "We just prompt Claude and ship the tests" workflow is missing the entire Meta recipe. Generated tests that don't kill injected mutants are tests that can't detect real bugs.
Generation: The intent lesson
A second 2025 result reinforces the same point from a different angle. Test Intention Guided LLM-based Unit Test Generation (Nan, Guo, Liu, Xia at ICSE 2025) introduced IntUT. Instead of prompting "write tests for this code," the system first extracts explicit test intentions: the inputs, the mock behaviors, the expected results.
On industrial Java projects, intention-guided generation beat plain prompting on coverage and real-bug detection.
For a Playwright stack, the lesson translates directly. Stop asking the agent to "write tests for the checkout flow." Start asking it to write a test with this cart state, this authenticated user, this network mock, and this expected redirect.
Our deeper walkthrough of this pattern lives in the Claude Code with Playwright guide, and similar patterns work with Cursor plus Playwright if that's your stack.
Here's what an intention-first prompt looks like in practice.
// prompt.md sent to Claude Code
//
// Goal: write a Playwright test for the `CheckoutPage` page object.
// Intention:
// - input state: cart has 2 items totalling $47.00, user is authenticated as `[email protected]`
// - mocks: POST /api/payments returns 402 on first call, 200 on retry
// - expected: UI shows retry banner, second POST succeeds, user lands on /order-confirmed
// Constraints:
// - use the existing CheckoutPage fixture in tests/fixtures/checkout.ts
// - no sleeps, only auto-waiting locators
// - one .spec.ts file, one test() block
The agent's output then runs a mutation-score gate, a compile gate, a linter pass, and a required human reviewer. No exceptions.
What does generation actually cost?
The honest answer is that you need to measure it in your own pipeline, because token counts vary wildly by page object size and project context.
The one cost number with a real citation behind it is from Agentless: Demystifying LLM-based Software Engineering Agents (Xia, Deng, Dunn, Zhang, FSE 2025), which reported $0.34 per issue on SWE-bench Lite with a non-agentic 3-phase pipeline. That's the best public benchmark for "what this kind of work costs when a research team optimizes it end-to-end."
Your real-world generation costs will scale with two things:
- Token volume per prompt (page object, existing tests, project context)
- How many filter rounds you run (mutation score, compile check, linter).
Budget conservatively, meter in production, and compare the monthly line item to one SDET-hour. Anything else is guessing.
Maintenance: the self-heal trap
Maintenance agents promise to fix your broken tests automatically. That promise hides a serious risk.
Imagine two checkout buttons in your app. One renders for trial users with data-testid="checkout-trial". Another render for paid users with data-testid="checkout-paid". They use different payment gateways and different server-side flows.
A frontend refactor renames checkout-trial to checkout-start. Fourteen tests fail. An auto-heal agent looks at what's on the page during its heal run, sees the paid flow, and updates all 14 tests to use checkout-paid.
The tests pass. The trial-flow bug nobody notices escapes to production.
This is the masked-regression problem, and it's why reducing test maintenance has to follow a propose-diff-then-approve pattern.
# .github/workflows/test-heal.yml (excerpt)
- name: AI suggest fix
run: npx ai-heal --propose-only > proposed-patches.diff
- name: Comment on PR
run: gh pr comment --body-file proposed-patches.diff
# Humans review. Nothing auto-commits. Ever.
Warning: An AI maintenance agent that can auto-commit to your default branch is a liability, not a feature. Turn that setting off before anyone discovers it the hard way.
What works in triage and exploration
Triage is the quiet win. Exploration is the loud demo.
Triage: The category with the best ROI right now
Raw Playwright CI output is the wrong input for an LLM. Thousands of lines of stack traces, DOM dumps, and retry noise. No history. No grouping. Any LLM fed directly will hallucinate a plausible-looking root cause roughly half the time, which is a nuisance your CI pipeline does not need.
Triage agents work when they consume structured inputs: grouped error fingerprints, trace context, historical pass/fail patterns for the same test over the last 30 days, and a signal about whether this test has ever passed in this CI environment.
Compare two prompts fed to the same LLM:
Bad prompt (raw output)
Here are the full logs from a failing Playwright run.
[50,000 tokens of interleaved stdout/stderr]
What went wrong?
Good prompt (structured input)
Test: tests/checkout.spec.ts > should retry on 402
Error fingerprint: TimeoutError @ locator('text=Retry') (seen 47 times in last 7 days)
Historical pattern: passed 312 times, failed 47 times (all failures on chromium-webkit parity suite)
Trace highlights: 402 API returned, retry button rendered at t=4.2s, click fired at t=4.3s, assertion at t=4.4s
Last passing run: 2 hours ago, same branch
Recent code changes: PR #2847 touched checkout-form.tsx
Please classify: bug / flaky / environmental, and propose the single most likely cause.
The second prompt produces something useful. The first produces confident guesswork.
The bottleneck for triage isn't the LLM. It's the layer that produces the structured input. Our deeper read on that layer is in Playwright root cause analysis and the debug Playwright tests guide.
The Playwright 1.59 CLI trace tools help here too: an agent can run npx playwright trace actions --grep="expect" and pull the exact failing assertion into its prompt without the operator copy-pasting logs.
Exploration: Promising but not production-ready yet
Autonomous browser agents look incredible in demos. Give browser-use or Stagehand a login and a goal, and watch them click through. The video is compelling.
The research is less kind.
In BrowserArena, a live evaluation of real open-web tasks, top agents handle simple searches fine and collapse on realistic multi-step flows. The BrowserGym line of work reports GPT-4o achieving around 41% success on the WebGames benchmark, while humans hit around 96%. That's a 55-point gap in spatial grounding and element manipulation.
The sharper finding comes from the WebTestBench paper (arXiv 2603.25226, early 2026). It reframes the question that matters for QA specifically: computer-use agents are typically benchmarked on task completion rather than defect detection. Those are different skills. An agent can book a flight successfully while walking right past a broken pricing display. For QA, only the second skill counts.
Tip: If you want to run exploration agents this year, scope them to monitoring, not testing. Fire them nightly against staging, log every anomaly to a ticket queue, and have a human review in the morning. Don't gate releases on them.
A starting stack for anyone piloting exploration: Stagehand or browser-use for navigation, Playwright's trace viewer for the evidence trail, and a human review queue for the output. Don't wire it into PR checks.
The failure modes nobody talks about
Each of the 4 failure modes below has a 2025 research behind it. Most "AI agent testing" content never mentions any of them.

1. The oracle problem: LLMs freeze bugs into your tests
When an LLM writes an assertion for your test, a critical question is whether the assertion captures what the code should do or what the code currently does.
In Do LLMs generate test oracles that capture the actual or the expected program behaviour? (Konstantinou, Degiovanni, Papadakis, ICST 2025), The answer is unambiguous. LLMs generate oracles that reflect the current implementation rather than the intended behavior.
Consequence: If your code has a bug at the moment you generate the test, the assertion locks the bug in as "expected." The test passes forever. The regression suite can no longer catch the problem.
Guardrail: Never generate oracles against code that hasn't been reviewed. Run mutation testing on generated tests; any test that survives a bug-injected mutant is suspect. Developer-like test and variable naming conventions, per the same paper, help the LLM lean closer to intent.
2. Trajectory signatures: Failures have a detectable shape
When an agent gets stuck, you can see it in the action log before it appears in the output.
A Study of Thought-Action-Result Trajectories (Software Lab, ASE 2025) mined n-gram patterns from thousands of agent runs.
The productive pattern is a tight 4-gram: Explore → Locate → GenerateFix → RunTests.
Failed trajectories are consistently longer and higher-variance than successful ones. Agents that loop on Explore → Explore → Explore are usually about to fail.
Guardrail: Log every action your agent takes. Track trajectory length distribution. Set an early-terminate threshold at roughly 1.5x the median successful run length. Most teams skip this instrumentation entirely, which means they discover stuck agents only after the LLM budget spikes.
3. Benchmark leakage: your favorite "AI beats humans" stat is probably inflated
Every vendor deck quotes benchmark numbers. Most of those numbers are contaminated.
In ULT: Benchmarking LLMs for Unit Test Generation from Real-World Functions (Huang, Zhang, Harman, Du, Ng), the authors built a decontaminated benchmark by sourcing 3,909 real-world Python functions from The Stack v2 and filtering out anything with tests already in LLM training data.
On older leaked benchmarks, LLMs hit around 92% accuracy, 82% branch coverage, and 50% mutation score. On ULT, the same LLMs dropped to 41% accuracy, 30% branch coverage, and 40% mutation.
The gap is leakage, not capability.
Guardrail: When a vendor quotes a benchmark number, ask three questions. What's the cutoff date of the benchmark? How was contamination controlled? Are they reporting branch coverage or just line coverage, and is the mutation score included? If any answer is hand-wavy, discount the number heavily.
4. Flaky detection has a ceiling: Code-only LLM prompts aren't enough
Flaky test detection looks like an obvious LLM win. It isn't.
FlakyLens (OOPSLA 2025, Proc. ACM Programming Languages Vol. 9, Article 320) showed LLM classifiers rely heavily on syntactic token attribution. They fixate on tokens such as Thread.sleep, await, or setTimeout and classify based on keyword presence. Semantics-preserving code perturbations drop accuracy by around 8.7 points. The authors also found a prior SOTA paper with a data leakage flaw in its F1 calculation; the original repo was quietly updated after disclosure.
The pattern generalizes: a generic LLM prompt cannot reliably tell a flaky test from a deterministic one. Historical run data can.
Guardrail: Treat LLM flaky-detection prompts as a weak signal at best. The reliable signal is a 30-day pass/fail history plus a flip-rate threshold. Our flaky test benchmark analysis walks through that math, and the Playwright flaky tests guide covers the Playwright-specific detection patterns.
A research-grounded adoption sequence
You don't adopt all four categories at once. You stagger them.
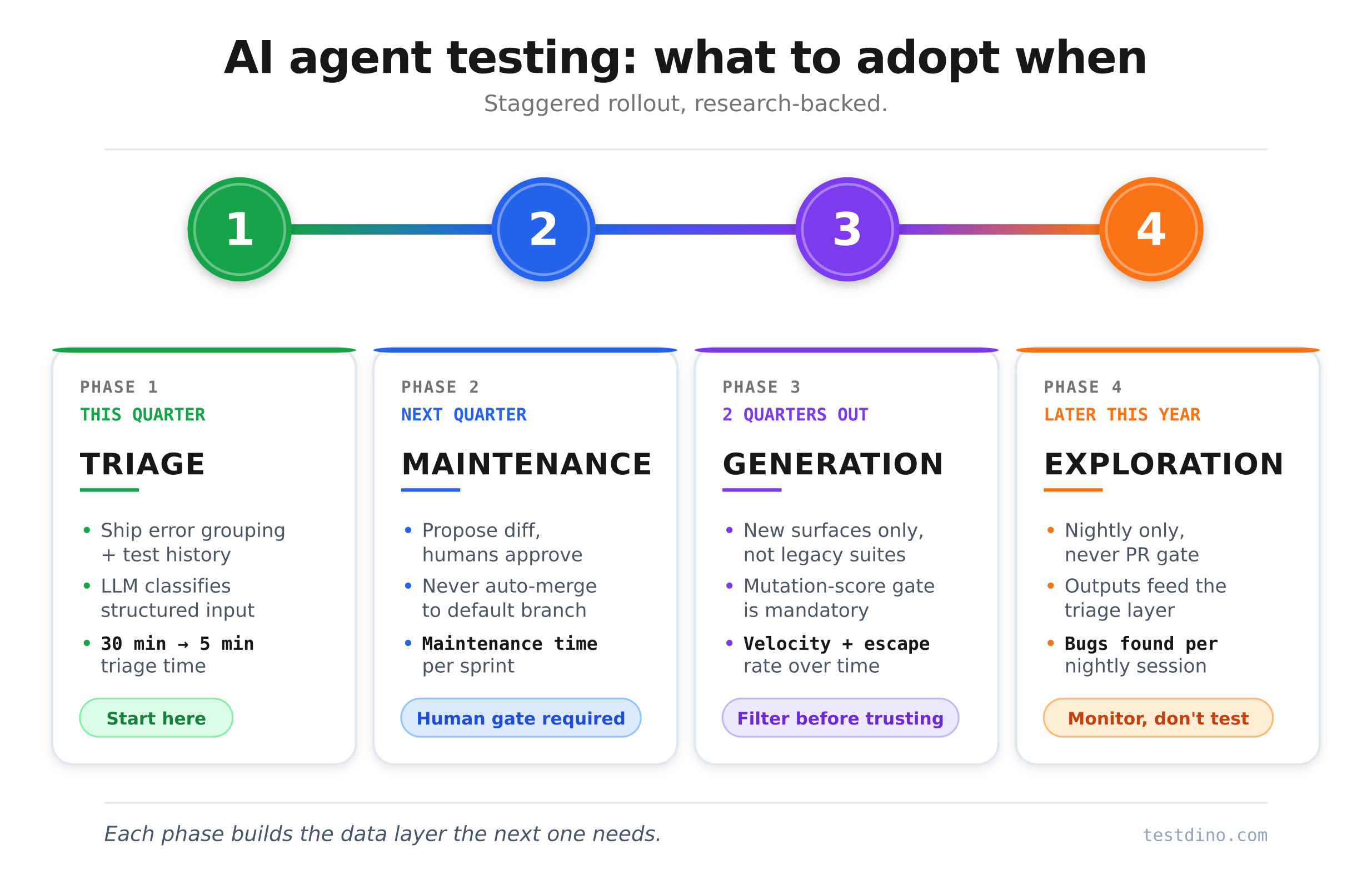
Phase 1 (This quarter): Triage first
Triage agents are the lowest-risk, fastest-ROI option for almost every team. The bottleneck is the data layer, not the LLM. Ship the substrate first: error grouping, trace context, test history. Wire an LLM on top of that structured input. Measure triage time per failure before and after. Most teams see a drop from 30 minutes to under 5 minutes on recurrent failure classes.
Phase 2 (Next quarter): Maintenance behind a human gate
Once triage is producing useful output, layer in maintenance agents. The critical word is behind. Propose diff, comment on the PR, let humans approve. Every auto-merge path is a future silent regression waiting to escape.
Phase 3 (2 quarters out): Generation on new surfaces only
Add generation agents for new test surfaces, not legacy suites. The mutation-score gate is non-negotiable. The oracle problem mentioned above bites hard on pre-existing buggy code.
Phase 4 (Later this year): Exploration last
Only adopt exploration agents once triage is mature. Exploration output feeds back through the triage layer. Without that, you'll drown in false positives.
The Agentless reality check
Before you build anything agentic, remember the Agentless result from earlier: a non-agentic 3-phase pipeline (localize, repair, validate) beats full agent frameworks on SWE-bench Lite at the same cost-per-issue number we cited above.
Translation: reach for an agent when your task requires exploration. Reach for a pipeline when your task is localizable. Most testing tasks are localizable. Start there.
What to measure before and after
Five metrics tell you if any of this is working:
- Triage time per failure (minutes). Should drop meaningfully in Phase 1.
- Flaky test ratio over 30 days (percentage of your suite that flips). Phases 1 and 4 both move this.
- Test authoring velocity on new surfaces (tests per engineer per day). Phase 3 moves this.
- Cost per PR (LLM tokens + CI minutes). Watch this spike in Phase 3 and 4.
- Production-bug escape rate. The only metric that matters in the end.
Our PR health and predictive QA posts go deeper on instrumenting metrics 1, 2, and 5.
The data layer that decides whether any agent works
Every category in this post depends on structured test artifacts.
- Triage agents need grouped errors and historical context.
- Generation agents writing Playwright tests need accurate runtime semantics, not scraped web pages.
- Maintenance agents need to know which selectors are stable versus which have flipped 12 times this week.
- Exploration agents need a downstream layer to file anomalies into, or their output disappears into log files no one reads.
This is the layer most commercial content treats as invisible.
TestDino's role is to supply it.
Error grouping clusters identical failures by fingerprint, so a triage agent sees one pattern instead of 50 duplicates. Test case history gives the agent 30, 90, or 365 days of pass/fail data to ground its classification in. The Playwright Skill exposes TestDino data and current Playwright runtime knowledge to any coding agent over MCP, so Claude Code or Cursor can write tests against real API semantics instead of outdated training data.
The takeaway
The 4 categories are the real shape of AI agent testing in 2026. The research is clear, LLMs are cheap now, trust is scarce, and the substrate matters more than the agent.
Pick one category this sprint. Pair it with one guardrail from the failure modes above. Measure one metric from the adoption sequence. That's the honest starting point.
If your sharpest pain is slow triage, start there with structured error grouping and historical test data underneath. If coverage is thin on a new feature, try generating with a mutation gate. If it's a flaky suite, fix the data layer first, then the LLM layer.
Everything else is vendor theater.
FAQs
Table of content
Flaky tests killing your velocity?
TestDino auto-detects flakiness, categorizes root causes, tracks patterns over time.
Follow Us







