Playwright Flaky Tests: How to Detect & Fix Them
A Playwright test that passes locally but fails in CI often signals flakiness or environment sensitivity, and it’s a frustrating problems This guide covers how to identify flaky tests using Playwright’s retry mechanism and apply targeted fixes including auto-wait patterns, stable locators, and network mocking.

Rerun, merge, move on. That's the flaky tax.
Those retries add up fast. Developers stop trusting red CI, and real bugs start hiding behind noise.
Playwright's built-in retry mechanism can even make this worse if you use it without tracking what's actually being retried and how often.
This guide covers how to:
-
Detect Playwright flaky tests using retries and annotations
-
Fix the most common root causes (timing, selectors, shared state, network)
-
Set up monitoring so flakiness doesn't grow silently
What makes a Playwright test "flaky"?
A Playwright flaky test passes on one run and fails on the next without any code changes. Same test, same code, different result.
Playwright has a specific definition. When you enable retries, a test that fails on the first attempt but passes on retry gets labeled "flaky" in the HTML report. Not "failed" -- specifically "flaky." That distinction matters:
- A failed test means something is broken
- A flaky test means something is unreliable
Atlassian lost over 150,000 hours of developer time per year to flaky tests. The real cost isn't CI minutes. It's trust. Once your team's default response to a red build is "just rerun it," you've already lost the battle.
The 6 root causes of flaky Playwright tests
Understanding test failure analysis starts with knowing which category you're in. The 6 root cause categories apply across all frameworks, but here's how each one shows up in Playwright specifically.
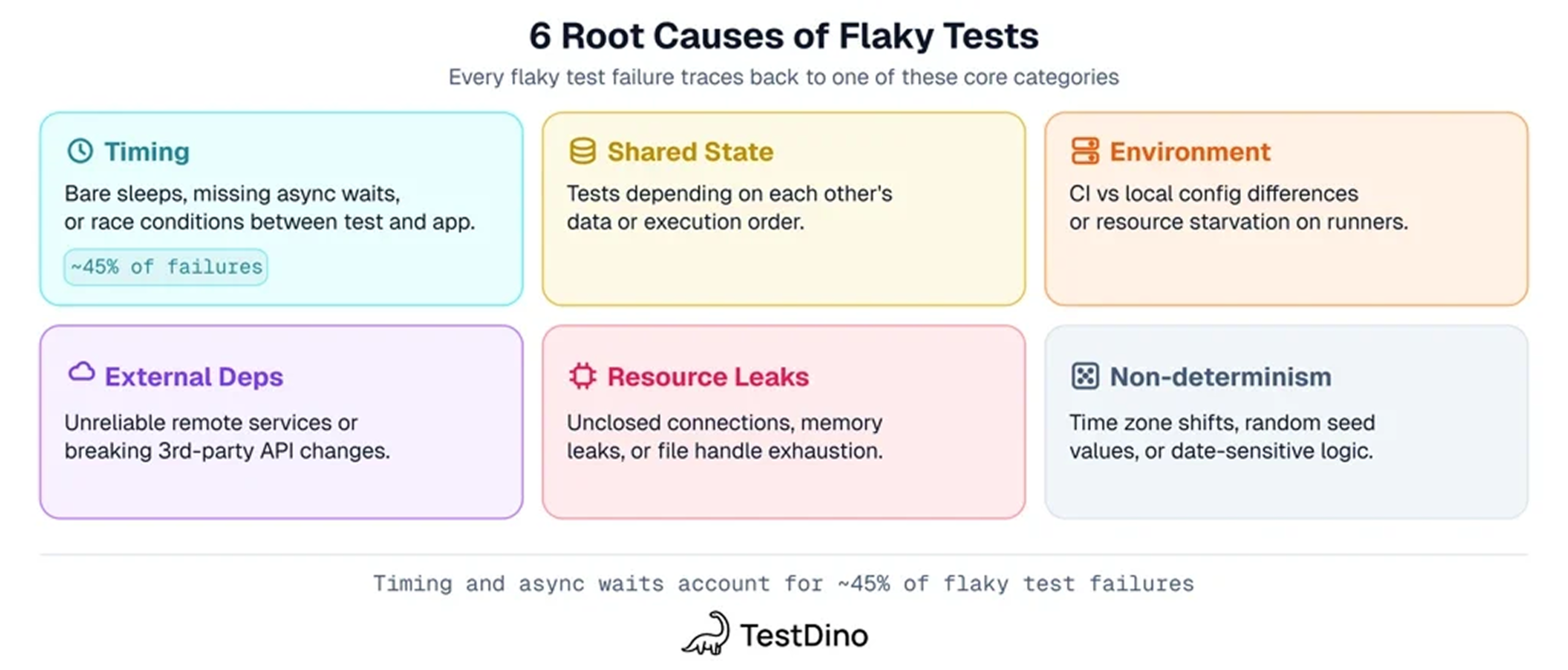
| Root cause | Playwright example |
|---|---|
| Timing (async wait issues) | waitForTimeout() instead of toBeVisible(), clicking before element is ready, missing await on async calls |
| Shared state (race conditions) | Shared state between parallel workers, browser context conflicts, test order dependency |
| Environment (platform differences) | Passes on macOS, fails on Linux CI runner, Docker /dev/shm exhaustion, browser-specific rendering |
| External dependencies (network) | page.goto() timeout on slow backend, flaky third-party API, waitForResponse race condition |
| Resource leaks | Unclosed browser contexts, connection pools growing across tests, duration drift over the suite |
| Non-determinism (time, randomness) | Timezone-dependent assertions, Math.random() edge cases, date logic that breaks on weekends |
What these look like in your codebase
Before jumping to fixes, you need to know which category you're dealing with. Here's how each root cause shows up in real code.
Timing
This is the big one. Playwright auto-waits on actions like click() and fill(), but it does NOT auto-wait on:
-
Custom DOM queries inside page.evaluate()
-
Assertions using raw expect() without Playwright matchers
-
locator.count() and locator.all(), which return a snapshot, not a live retrying result
-
ElementHandle methods, which execute immediately without waiting
That's where most timing flakes hide. The fix is almost always replacing snapshot methods with web-first assertions.
There's a subtler timing bug worth knowing: missing await on async Playwright calls. When a click() or fill() isn't awaited, it runs at the same time as the rest of the test instead of before it. This is common enough that Playwright's official best practices recommend turning on the @typescript-eslint/no-floating-promises ESLint rule. We'll cover that in the prevention section.
Shared state and race conditions
Picture this: 2 tests create orders in the same database table. One asserts "1 order exists," but the other test's order is already there. Works with --workers=1, breaks in parallel.
Playwright creates a fresh BrowserContext per test, which handles cookie and session isolation for you. But database records, server-side state, and file system artifacts are not isolated by Playwright. That's your job to handle.
Animation timing
Playwright's actionability checks do wait for elements to be stable and not covered by other elements. But animation flakes still happen when the app isn't ready even after an element becomes clickable, or when overlays pop up between the readiness check and the actual click. Think of this as a diagnostic signal rather than a root cause on its own -- the Playwright-specific fix is in the overlays section below.
Resource-affected flaky tests: when CI infrastructure is the root cause
Here's a finding that surprises most teams. A study covering 52 projects found that 46.5% of flaky tests are RAFTs (Resource-Affected Flaky Tests). In a RAFT, the test passes or fails based on how much CPU, memory, or I/O the machine has at runtime -- not based on your code.
In Playwright, this looks like tests passing on your M1 Pro but failing on a shared 2-core CI runner, inconsistent results across shards, or tests that only fail when running in parallel.
Nearly half of flaky tests are an infrastructure problem, not a code problem. If your tests pass locally but fail in CI, check runner resources before rewriting any selectors.
You can simulate a slow CI runner locally using CDP session throttling:
test.beforeEach(async ({ page }) => {
const context = page.context();
const cdpSession = await context.newCDPSession(page);
await cdpSession.send('Emulation.setCPUThrottlingRate', { rate: 4 });
});Start with 4-6x throttle and adjust based on your CI runner specs. If tests start failing with throttling on, you've found RAFTs. This technique should be part of every Playwright team's debugging toolkit.
How to detect Playwright flaky tests
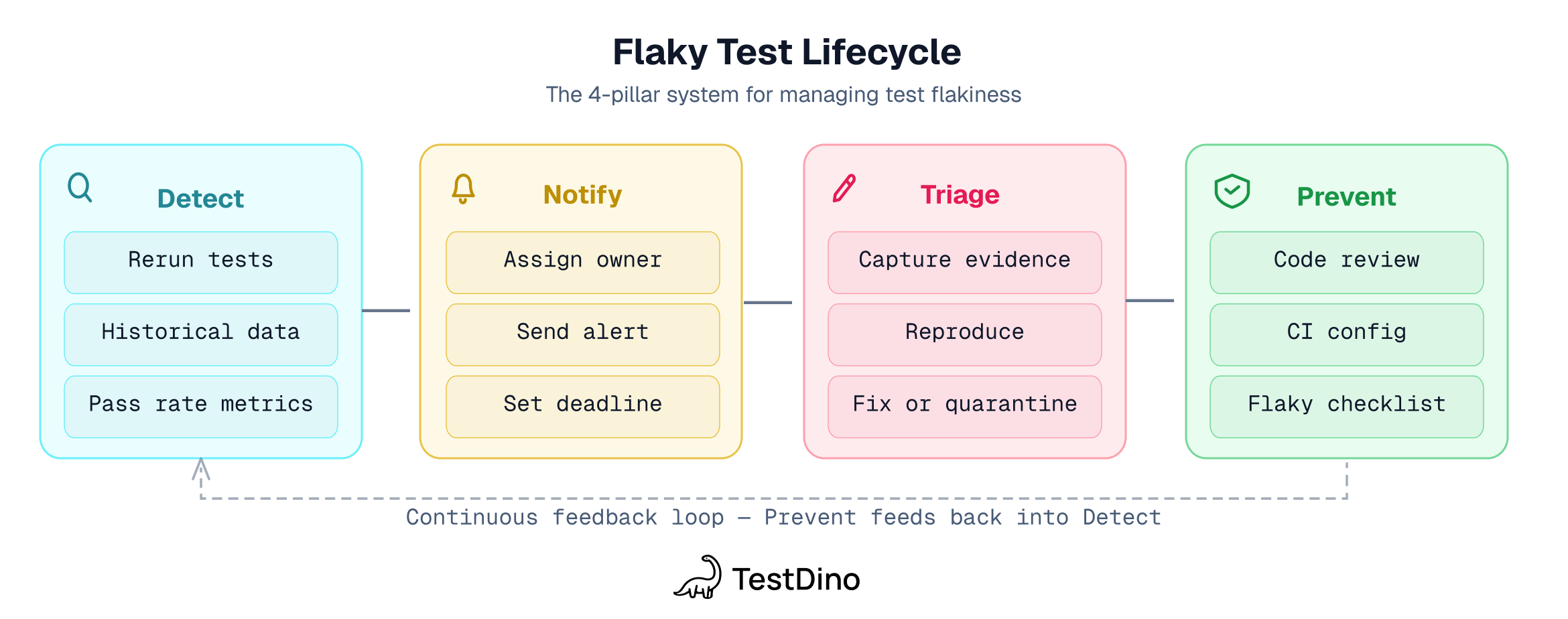
Detection is the first pillar of the 4-pillar framework. You can't fix what you can't see.
Built-in Playwright detection
Playwright gives you a few native ways to surface flaky tests.
Enable retries in your config:
// playwright.config.ts
export default defineConfig({
retries: process.env.CI ? 2 : 0,
});With retries on, Playwright tags any test that fails and then passes on retry as "flaky" in the HTML report. You can filter by this label directly.
Stress test with --repeat-each:
# Run each test 10 times to surface instability
npx playwright test --repeat-each 10
# Full stress test: high parallelism and stop on first failure
npx playwright test --repeat-each 100 --workers 10 -x --fail-on-flaky-tests --retries=2
# Use workers=1 to rule out parallelism as the cause
npx playwright test --repeat-each 10 --workers 1The --fail-on-flaky-tests flag is underused. It treats any test that needs a retry to pass as a failure -- even if it eventually went green. Run this before merging to block flaky tests from entering the codebase, and pair it with your PR health checks.

Tip: Disable retries while investigating. Set retries: 0 temporarily. Otherwise retries mask the flakiness you're trying to find.
Tip: Use page.pause() to freeze execution mid-test and inspect the page interactively. This is especially useful when a test passes locally but you can't figure out why it fails in CI.
How to use trace viewer to debug a flaky test
Once Playwright flags a test as flaky, your next step is the trace viewer. Open playwright-report/ in your browser after a test fails and retries. Click the failing test, then click the "Traces" tab.
The timeline shows every action, screenshot, and network request in order. Find the action that happened just before the failure.
- If you see a click firing before an element is stable: that's a timing issue
- If you see a waitForResponse that never resolves: that's the promise ordering problem
- If you see a network request that never came back: that's an external dependency race
The trace shows you the exact point where the test diverged from what you expected. You don't need to guess.
The gap in single-run detection
Each CI run is isolated. You can see what broke today. But you can't see whether a test has been flaking for 6 weeks, whether it only fails on Ubuntu runners, or whether it started after a specific commit.
Answering those questions requires historical data across multiple runs. Single-run HTML reports can't give you that.
Here's what each detection method can and can't tell you:
| Method | What it tells you | What it can't tell you |
|---|---|---|
| Playwright built-in (retries + HTML report) | Which tests flaked in this run | Whether this is a one-time flake or a pattern |
| --repeat-each stress testing | Whether a test is unstable under load | Whether it flakes in real CI conditions |
| Analytics tools (TestDino, etc.) | Stability trends, root cause classification, environment correlation | Depends on having enough historical run data |
One finding worth knowing: research on co-occurring test failures found that 75% of flaky tests belong to failure clusters. They tend to fail together and share an underlying cause. When 1 test flakes, look at what else failed in the same run. Instead of investigating 100 individual failures, you end up fixing 3 root causes.
TestDino's AI-native test intelligence handles this grouping automatically across runs. If you want to query that data directly from your editor, the Playwright MCP server lets you ask "which tests flaked most this week" or "what changed before this test started failing" without leaving your IDE.
Playwright-specific fixes that eliminate flakiness
Each fix below maps to a root cause from the table above. These are Playwright API patterns, not general advice.
Learn more about Playwright automation best practices and the Playwright automation checklist that pairs with this guide. If you want a deeper foundation before diving into fixes, the Playwright skill guide covers the framework's core mechanics.
Replace arbitrary waits with web-first assertions (fix this first)
This single change eliminates roughly 45% of flaky tests. Start here.
// This will flake
await page.waitForTimeout(2000);
await page.click('button#submit');
// This won't
await expect(page.getByRole('button', { name: 'Submit' })).toBeVisible();
await page.getByRole('button', { name: 'Submit' }).click();Before Playwright acts on any element, it runs 5 checks: the locator resolves to exactly 1 element, the element is visible, it's stable (not animating), it can receive events (nothing is covering it), and it's enabled. Those checks are built into every click(), fill(), and check() call.
Playwright has 26+ auto-retrying web-first assertions. These are the ones you'll use most:
| Assertion | What it checks |
|---|---|
| toBeVisible() / toBeHidden() | Element visibility |
| toBeEnabled() / toBeDisabled() | Interactive state |
| toHaveText() / toContainText() | Text content |
| toHaveValue() | Input value |
| toHaveCount() | Number of matching elements |
| toHaveAttribute() | HTML attribute |
| toHaveURL() / toHaveTitle() | Page-level checks |
If you're calling .textContent(), .getAttribute(), or .isVisible() and then asserting on the result with plain expect(), you're bypassing all of that.
// BAD: snapshot, no retry
const text = await page.locator('#status').textContent();
expect(text).toBe('Complete');
// GOOD: auto-retries until text matches or times out
await expect(page.locator('#status')).toHaveText('Complete');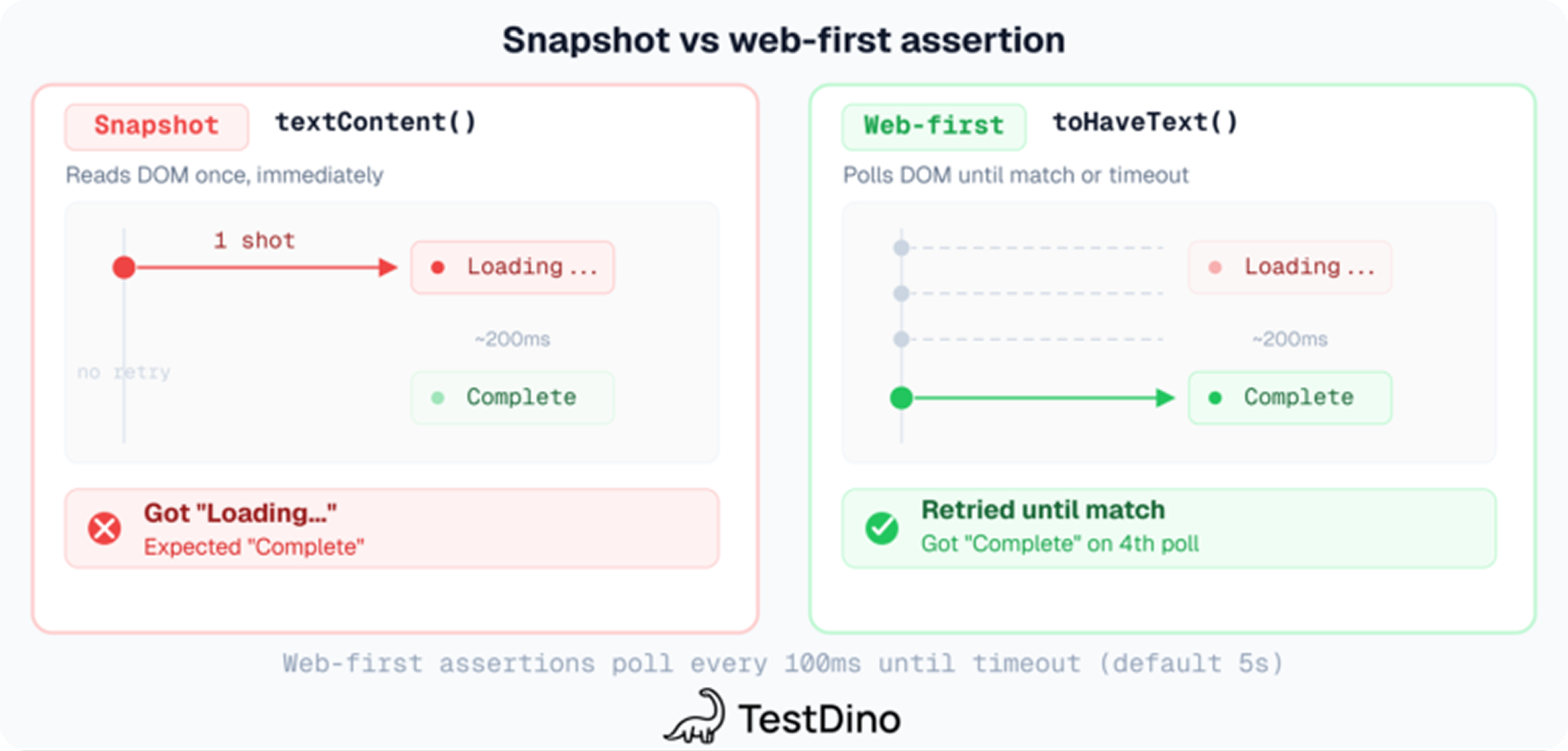
Here's the difference. textContent() is a one-shot read. It grabs whatever text is in the DOM at that exact millisecond and returns it. If the UI hasn't updated yet, the assertion fails -- even if the text would have been correct 100ms later.
expect(locator).toHaveText() works differently. It polls the locator repeatedly until the text matches or the timeout expires (default: 5 seconds). It waits naturally for async updates, animations, and data fetches to settle.
One more note: waitForTimeout() is sometimes acceptable for third-party UI components with CSS animations that Playwright can't introspect. But it doesn't fix the root cause -- it just masks it. Prefer disabling animations via reducedMotion: 'reduce' in your config (covered below) or waiting for the animation to complete through a programmatic check.
Fix race conditions with the promise-first pattern
This is Playwright's most common race condition. Most teams hit it eventually.
// BAD: response might arrive before we start listening
await page.click('#submit');
const response = await page.waitForResponse('/api/save');
// GOOD: register the listener BEFORE triggering the action
const responsePromise = page.waitForResponse('/api/save');
await page.click('#submit');
const response = await responsePromise;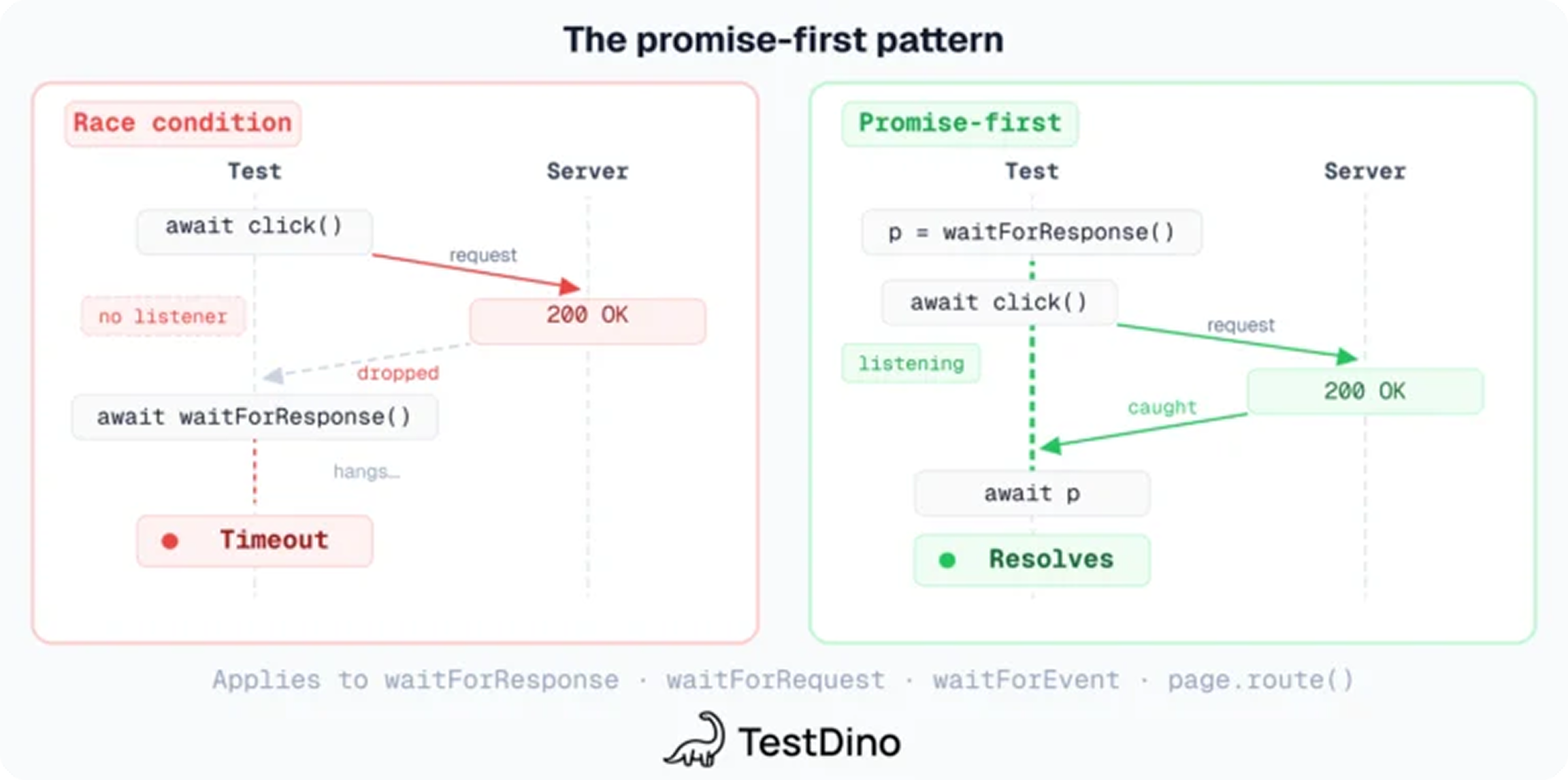
Here's what goes wrong in the bad version. When you click the submit button, the browser sends the request and the server responds. If the response comes back before waitForResponse() starts listening, Playwright never sees it. The promise never resolves. The test hangs until timeout.
The fix is simple: register the listener before you fire the action. The promise captures the response regardless of how fast the network is.
This "promise-first, action-second" pattern applies to waitForResponse, waitForRequest, and waitForEvent. The one exception is waitForURL -- it checks persistent browser state, not an event, so it's safe to call after the navigation.
The same rule applies to page.route(). Set up route handlers before the navigation that triggers requests:
// BAD: route might miss the request
await page.goto('/dashboard');
await page.route('/api/data', route => route.fulfill({ body: '[]' }));
// GOOD: route set up before navigation
await page.route('/api/data', route => route.fulfill({ body: '[]' }));
await page.goto('/dashboard');Handle overlays, toasts, and animations
Playwright checks that an element can receive events before acting on it. But overlays still cause flakes in 3 situations: they appear between test steps, they cover the element you're trying to click, or they need to be dismissed as part of the app flow.
For overlays you know will appear, wait for them to go away first:
// Wait for the loading spinner to disappear before clicking
await page.locator('.loading-spinner').waitFor({ state: 'hidden' });
await page.click('#submit');For overlays that show up unpredictably -- cookie banners, notification toasts, permission prompts -- use page.addLocatorHandler(). It automatically dismisses the overlay whenever it appears, without any changes to your test logic:
await page.addLocatorHandler(
page.getByRole('button', { name: 'Accept cookies' }),
async () => {
await page.getByRole('button', { name: 'Accept cookies' }).click();
}
);For CSS animations, disable them globally in your config:
// playwright.config.ts
use: {
reducedMotion: 'reduce',
}This uses Playwright's built-in emulation option and works across all 3 browsers. Most well-built apps already respect the prefers-reduced-motion media query. Add this 1 line and most animation flakiness goes away.
A note on iframes and Shadow DOM. Playwright pierces the Shadow DOM by default, so you rarely need special handling there. Iframes are different. When a frame detaches or reloads mid-test, Playwright loses its reference and throws a "frame detached" error. Always use page.frameLocator() to reference frames. It re-fetches the frame automatically if it becomes stale, instead of failing.
Use stable locators
A fragile selector breaks the moment a developer renames a CSS class or restructures the DOM. A stable locator is tied to meaning, not implementation.
// Fragile -- breaks when CSS changes
await page.locator('.btn-primary').click();
// Stable -- tied to the button's role and visible label
await page.getByRole('button', { name: 'Submit' }).click();
// Also stable
await page.getByTestId('submit-button').click();
await page.getByLabel('Email address').fill('[email protected]');One important distinction: Locator and ElementHandle are not the same thing. ElementHandle (returned by page.$()) points to a specific DOM node at a specific moment in time. It doesn't retry. It doesn't wait. If the DOM updates after you capture it, your reference is stale.
Locator is a description of how to find an element. Every time Playwright uses it, it re-evaluates the selector and runs auto-wait checks. This is why Playwright's docs explicitly discourage ElementHandle for anything beyond basic scripts.
Strict mode matters here. By default, Playwright locators are strict: if a locator matches more than 1 element, it throws an error. Don't "fix" this by adding .first(), .last(), or .nth() -- those just hide the problem. If element order changes in the UI, your test silently clicks the wrong thing. Instead, filter by text, aria-role, or a test ID to make your locator uniquely identify the right element.
Isolate every test
Test order dependency is one of the trickiest flakiness sources because it only appears when test order changes -- like when you enable parallel execution. For a deeper look at structuring tests so they stay independent, see the Playwright test management guide.
// BAD: depends on data created by a different test
test('view profile', async ({ page }) => {
await page.goto('/profile/user-created-by-other-test');
});
// GOOD: creates its own data, doesn't rely on anyone else
test('view profile', async ({ page, request }) => {
const response = await request.post('/api/users', {
data: { name: 'Test User' }
});
const user = await response.json();
await page.goto(`/profile/${user.id}`);
});Every test creates what it needs, uses it, and cleans up. The rule is simple: if your test needs data, it creates it. If test A needs to run before test B for B to pass, that's a design problem, not a sequencing preference.
Mock network dependencies
External APIs add variability: inconsistent response times, outages, rate limits. For any API call that isn't the system under test, mock it. Playwright API testing covers the full range of network patterns, but the core mock is straightforward:
await page.route('**/api/users', (route) => {
route.fulfill({
status: 200,
contentType: 'application/json',
body: JSON.stringify({ users: [{ id: 1, name: 'Alice' }] }),
});
});Mock third-party services: payment gateways, email providers, analytics. Don't mock critical end-to-end paths where you're validating real integrations -- that defeats the purpose.
One gotcha most teams hit: service workers. A service worker in the browser can intercept requests before page.route() ever sees them. This creates mock failures that look completely random. Block service workers explicitly:
const context = await browser.newContext({
serviceWorkers: 'block',
});Control time to stop clock-dependent flakes
Time-based flakiness is more common than most teams expect. Consider a test that queries "todos due in the next hour" -- it gets different results depending on when it runs. GitHub's team found tests that assumed February has 28 days, which passed for 3 years and then failed every leap year. There are also tests that break at midnight and during daylight saving transitions.
The shared root cause: the test depends on the system clock, which changes across environments and calendar dates.
Use Playwright's Clock API to freeze Date.now() and take full control of setTimeout and setInterval:
// Freeze time to a fixed date to prevent weekend or end-of-month edge cases
await page.clock.install({ time: new Date('2026-03-18T10:00:00') });
await page.goto('/dashboard');
await expect(page.getByText('Wednesday, March 18')).toBeVisible();
// Fast-forward time to trigger a 5-minute timeout instantly
await page.clock.fastForward('05:00');
await expect(page.getByText('Session Expired')).toBeVisible();This removes the system clock from the equation entirely. Your test isn't waiting 5 real minutes -- it's telling the browser that 5 minutes have passed. The test runs deterministically every time regardless of the machine's timezone, the day of the week, or how fast the CI runner is.
Configure Playwright timeouts the right way
Playwright has 4 separate timeout settings. Most teams only configure 1. Configuring all 4 prevents a whole class of false failures. This pairs well with the Playwright reporting runbook for keeping CI feedback fast and readable.
// playwright.config.ts
export default defineConfig({
timeout: 60_000, // 60s per test
expect: {
timeout: 10_000, // 10s for individual assertions
},
use: {
actionTimeout: 15_000, // 15s for clicks, fills, checks
navigationTimeout: 30_000, // 30s for page.goto()
},
retries: process.env.CI ? 2 : 0,
});If page.goto() keeps timing out in CI, switch from the default load event to domcontentloaded. The load event waits for every resource on the page -- images, fonts, iframes, third-party scripts -- to finish downloading. In CI that's 2-5x slower than on your local machine. domcontentloaded fires as soon as the HTML is parsed, which is almost always what you actually need:
await page.goto('/dashboard', { waitUntil: 'domcontentloaded' });For tests you know are slow (big data exports, heavy DB operations), use test.slow() instead of raising the global timeout:
test('heavy data export', async ({ page }) => {
test.slow();
// this test gets 3x the default timeout, the rest of your suite is unchanged
});Tune parallel execution
Running too many workers on a CI runner causes resource starvation -- that's the RAFT problem. For large suites, Playwright sharding distributes work across jobs rather than piling more workers onto a single machine.
// playwright.config.ts
export default defineConfig({
workers: process.env.CI ? 2 : undefined,
fullyParallel: false, // file-level parallelism only
});fullyParallel: true runs tests within the same file in parallel. This breaks any test that depends on execution order within a file. Start with file-level parallelism and opt into within-file parallelism only when you've confirmed those tests are truly independent:
test.describe('independent cart tests', () => {
test.describe.configure({ mode: 'parallel' });
test('add item', async ({ page }) => { /* ... */ });
test('remove item', async ({ page }) => { /* ... */ });
});If tests pass with --workers=1 but fail with --workers=4, you have either shared state or resource contention. Shared state needs the isolation fix from above. Resource contention needs fewer workers or more CI resources.
How to prevent flaky Playwright tests
Fixing existing flakes is half the job. The other half is stopping new ones from entering the codebase. This is the Prevent pillar of the 4-pillar framework. Here are the API-level prevention patterns.
Watch out for locator.all()
This trips up experienced Playwright teams. locator.all() does not auto-wait. It returns whatever elements are in the DOM at that exact moment. If the list is still loading, you get a partial result and your loop processes the wrong number of items.
// This will flake if the list is still loading
for (const item of await page.getByRole('listitem').all()) {
await item.click();
}
// Safe: wait for the expected count first, then iterate
await expect(page.getByRole('listitem')).toHaveCount(5, { timeout: 10_000 });
for (const item of await page.getByRole('listitem').all()) {
await item.click();
}The Playwright docs explicitly warn about this, but the method's name makes it feel safe. It isn't.
Use expect().toPass() for multi-step assertions
Sometimes you need to retry a block of multiple assertions together, not just a single check. expect().toPass() retries the entire callback until it passes or times out:
await expect(async () => {
const response = await page.request.get('/api/status');
expect(response.status()).toBe(200);
expect(await response.json()).toHaveProperty('ready', true);
}).toPass({ timeout: 30_000 });One gotcha: without an explicit timeout, expect.toPass() defaults to timeout: 0 and ignores your custom expect timeout setting. Always pass a timeout here.
Use expect.poll() for values that change over time
When you're waiting for a value to reach a certain state -- like a counter incrementing or a list growing -- expect.poll() lets you retry the check on a polling schedule:
await expect.poll(async () => {
return await page.locator('.item').count();
}, { timeout: 10_000 }).toBeGreaterThan(5);Catch missing await with ESLint
An async Playwright call without await runs in parallel with the rest of the test instead of before it. That's a race condition introduced by a missing keyword.
Add this ESLint rule:
{
"rules": {
"@typescript-eslint/no-floating-promises": "error"
}
}This catches page.click() without await at the linting stage, before it ever becomes a flaky test. Run ESLint in CI alongside your tests.
Configure traces for CI debugging
Always record traces in CI. When a test fails on a runner you can't directly access, the trace is your only window into what actually happened. This connects directly to your test automation reporting workflow. For teams that need more than the default reporter output, a custom Playwright reporter can format failure data exactly how your team needs it.
// playwright.config.ts
export default defineConfig({
use: {
trace: 'on-first-retry',
screenshot: 'only-on-failure',
video: 'retain-on-failure',
},
});trace: 'on-first-retry' only generates a trace when a test needs a retry. Storage cost is low. Debugging value is high.
Full GitHub Actions workflow
# .github/workflows/e2e.yml
name: E2E Tests
on: [push, pull_request]
jobs:
test:
runs-on: ubuntu-latest
steps:
- uses: actions/checkout@v4
- uses: actions/setup-node@v4
with: { node-version: 20 }
- run: npm ci
- run: npx playwright install --with-deps
- run: npx playwright test --retries=2 --reporter=html
- uses: actions/upload-artifact@v4
if: always()
with:
name: playwright-report
path: playwright-report/The if: always() on the upload step matters. Without it, the report disappears on failed runs -- which is exactly when you need it most.
One more thing worth remembering: Playwright is your fastest user. If a test exposes a timing issue, a real user on a slow connection or old device can hit that same bug. Sometimes the right fix isn't in the test. It's in the app.
CI and infrastructure fixes
These patterns fix the environment and RAFT categories. These aren't changes to test code -- they're infrastructure changes.
Docker /dev/shm exhaustion
Chromium-based browsers use /dev/shm for shared memory between processes. Docker's default is 64MB, which is not enough for Chromium. When it runs out, you get random browser crashes that look like intermittent test failures. Playwright's Docker docs recommend using --ipc=host:
# Recommended: share the IPC namespace (Playwright's official recommendation)
docker run --ipc=host playwright-tests
# Alternative: increase the shared memory limit
docker run --shm-size=1g playwright-testsRun tests against production builds, not dev servers
Vite dev server and Next.js dev mode come with HMR (hot module replacement), error overlays, and hot-reload timing that can interfere with Playwright. These cause flakes that don't exist in the real app.
// playwright.config.ts
webServer: {
command: 'npm run build && npx serve dist -p 5173',
url: 'http://127.0.0.1:5173',
timeout: 60_000,
reuseExistingServer: !process.env.CI,
},Lock down the test environment
Unfixed viewport sizes, locales, and timezones are a quiet source of environment-specific failures. Lock them down in your config:
use: {
viewport: { width: 1280, height: 720 },
locale: 'en-US',
timezoneId: 'America/New_York',
},Browser-specific flakiness
WebKit works on Linux CI, but some rendering behavior differs from Safari on macOS. If Safari fidelity matters to your product, run WebKit tests on a macOS runner. In CI generally, optimize for reproducibility: start with workers: 1, shard across jobs when you need parallelism, and pin your Playwright version and Docker image instead of floating latest.
How to quarantine flaky tests in Playwright

Quarantine works, but only with accountability. This is the Triage pillar of the 4-pillar framework. The pattern breaks down when quarantined tests accumulate without owners or deadlines. At that point, you don't have a quarantined test -- you have a test you've silently deleted.
Tag it:
test('@flaky login flow under load', async ({ page }) => {
// test body
});You can also use Playwright annotations for structured metadata. Note that test.fixme() skips the test entirely -- use it when you want to stop running a test, not when you're actively quarantining it (quarantined tests should still run in a separate job).
Exclude from the main pipeline, run separately:
npx playwright test --grep-invert @flaky # main pipeline
npx playwright test --grep @flaky # separate non-blocking jobCreate a ticket immediately. Not tomorrow. Assign it to a specific person, not "the team." If a quarantined test isn't fixed within 2 sprints, escalate it. Either fix it or delete it. Teams using Playwright test management tools to track quarantine with ownership and due dates resolve flakes far faster than teams tracking them in spreadsheets.
Target to aim for: 95-98% pass rate and less than 2% flaky rate. These are operational guidelines, not hard rules.
How teams solved flaky tests at scale
Slack, GitHub, and Atlassian all arrived at the same approach: automate detection, quarantine with an assigned owner and a deadline, and track stability trends across runs rather than single-run reports. The details vary by company. The pattern doesn't vary.
- Slack built "Project Cornflake" to automate detection and suppression, dropping test job failure rate from 57% to under 4%.
- Atlassian built "Flakinator" for the Jira Frontend repo, which auto-quarantines flaky tests, assigns an owner via code ownership, and creates a Jira ticket with a deadline.
- GitHub went from 1 in 11 commits (9%) having a red build from a flaky test to 1 in 200 (0.5%), an 18x improvement.
- Meta built the Probabilistic Flakiness Score (PFS), treating flakiness as a spectrum rather than a binary.
What you can do: Automate detection. Quarantine with ownership. Give every test a stability score and track it over time. Tools like TestDino do this for Playwright out of the box. Data-driven QA isn't about fancy tooling. It's about making the problem visible so more people fix it.
Tracking progress: the metrics that matter
You can't reduce Playwright flaky tests by feel. Track these 5 numbers using your test automation reporting setup.
| Metric | What it measures | Target |
|---|---|---|
| Flaky rate | % of tests needing retries to pass | Below 2% |
| Failure rate | Total failures including real bugs | Below 5% |
| MTTR | Time from failure detection to fix deployed | Minimize |
| Duration trends | Tests getting slower over time | Stable or decreasing |
| Environment correlation | Failures tied to specific runners or environments | Identify and fix |
Here's what progress looks like when you're actively fixing flaky tests:
| Week | Pass rate | Flaky rate | Avg suite duration |
|---|---|---|---|
| 1 | 87% | 15% | 4m 23s |
| 2 | 91% | 11% | 3m 58s |
| 3 | 94% | 7% | 3m 45s |
| 4 | 96% | 3% | 3m 30s |
The duration drop is the part people miss. As flaky tests get fixed, retries disappear, and your total suite time shrinks. That's the ROI number your engineering manager wants to see.
Test reporting tools that track these across runs make patterns obvious. Without them, you're guessing.
Code review checklist for Playwright tests
2 minutes of review before merging catches most flaky tests before they ever touch the main branch. A full version of this lives in the Playwright automation checklist.
-
Does it use waitForTimeout() or page.waitForSelector() instead of web-first assertions?
-
Does it use CSS or XPath selectors instead of role-based locators?
-
Does it depend on data created by another test?
-
Does it call external APIs without mocking them?
-
Does it use locator.all() without waiting for the full list to load?
-
Does it use ElementHandle (via page.$()) instead of Locator?
-
Does it hardcode dates, random values, or timezone-sensitive logic?
-
Does it have tight timeouts that might fail on slower CI runners?
-
Is every async Playwright call properly awaited?
-
Does it set up waitForResponse or page.route() before the action that triggers the request?
Conclusion
If you're staring at a flaky suite and don't know where to start, here's your Monday plan. Enable --fail-on-flaky-tests in your pre-merge pipeline. Audit your top 5 flakiest tests using trace viewer. Then set up cross-run tracking so you see patterns instead of guessing.
Fix async waits first. Replace waitForTimeout() with web-first assertions -- this is almost always the highest-leverage fix. Then check your infrastructure (46.5% of flaky tests are resource-affected, so "it passes locally" isn't good enough). Use promise-first patterns for every waitForResponse and page.route() call. Then quarantine the rest with accountability: tag, exclude, ticket, assign, fix. In that order.
If you're deciding whether to pair this work with a broader automation testing tool change, do the code fixes first. The tooling decision is easier once you have a stable baseline.
FAQs
Stress test locally: npx playwright test --repeat-each 10 runs each test 10 times to surface instability.
Block flaky merges: npx playwright test --fail-on-flaky-tests --retries=2 treats any test that needed a retry as a hard failure. Combine with PR health checks.
Track across runs: use flaky test detection tools to calculate stability scores from historical CI data.

Savan Vaghani
Product Developer





