Stop guessing which tests are flaky.
TestDino detects flaky Playwright tests automatically through retry analysis and cross-run patterns, then tracks stability so you fix what matters first.

Flaky tests are eating your
pipeline time and team trust
Half the team ignores red builds and nobody knows which tests are actually unreliable.

Nobody knows which tests are actually flaky
Some tests fail intermittently but there is no definitive list. Someone added a test.skip annotation six months ago with a TODO that never got addressed. The suite has a trust problem with no data.
CI reruns are your unofficial flaky test strategy
Your pipeline retries failed tests two or three times. If it passes on retry, everyone moves on. Those retries cost CI minutes, slow the pipeline, and mask real failures.
Real failures get lost in flaky noise
A genuine regression fails a test, but the team assumes it's flaky because that test has failed before. The PR gets merged. The bug makes it to production.
No visibility into whether flaky tests improve
You fixed a flaky test last week. Is it still stable? There is no trend line, no stability score, no way to confirm your fix actually worked beyond hoping and manually watching CI.
Auto-detect flaky tests across runs.
Some tests keep flipping.
Flaky tests detected with root cause
How flaky test detection works
TestDino analyzes every test run for retry patterns, cross-run inconsistencies, and failure-to-pass transitions. Flaky detection starts from your very first run.
Add the TestDino reporter
One line in your Playwright config. Test results, retry data, and timing information flow to TestDino after every run. No wrappers, no new dependencies.

reporter: [ ['@testdino/playwright', { token: process.env.TESTDINO_TOKEN }], ]
npx playwright testRetry patterns are analyzed
When a test fails then passes on retry, TestDino flags it as flaky. Across multiple runs, TestDino builds a flaky rate for every test - the percentage of runs where it exhibited flaky behavior.

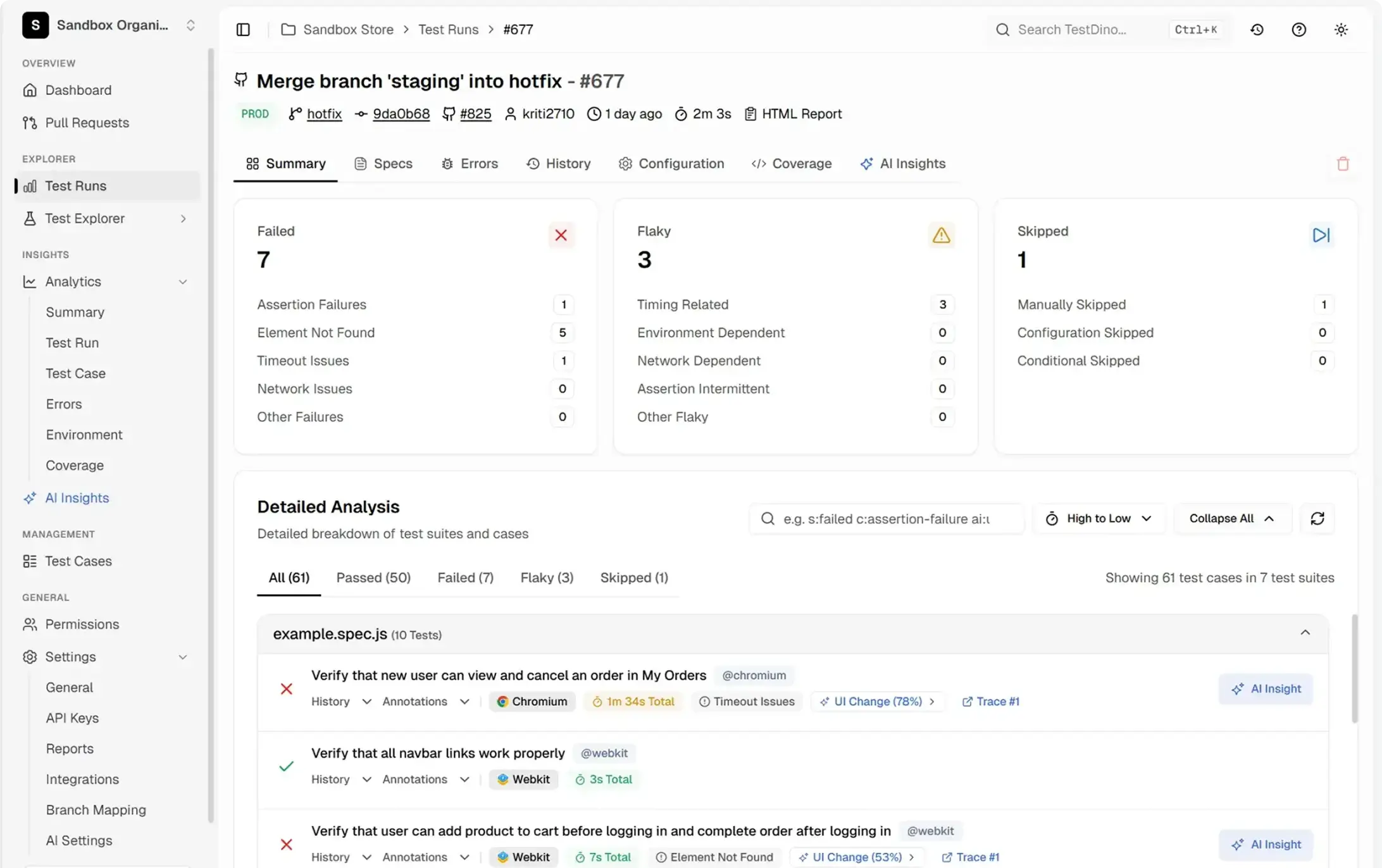
Review flaky tests by root cause
TestDino classifies likely root causes into five categories: timing related, environment dependent, network dependent, assertion intermittent, and other. See which tests are most flaky and what category they fall into.
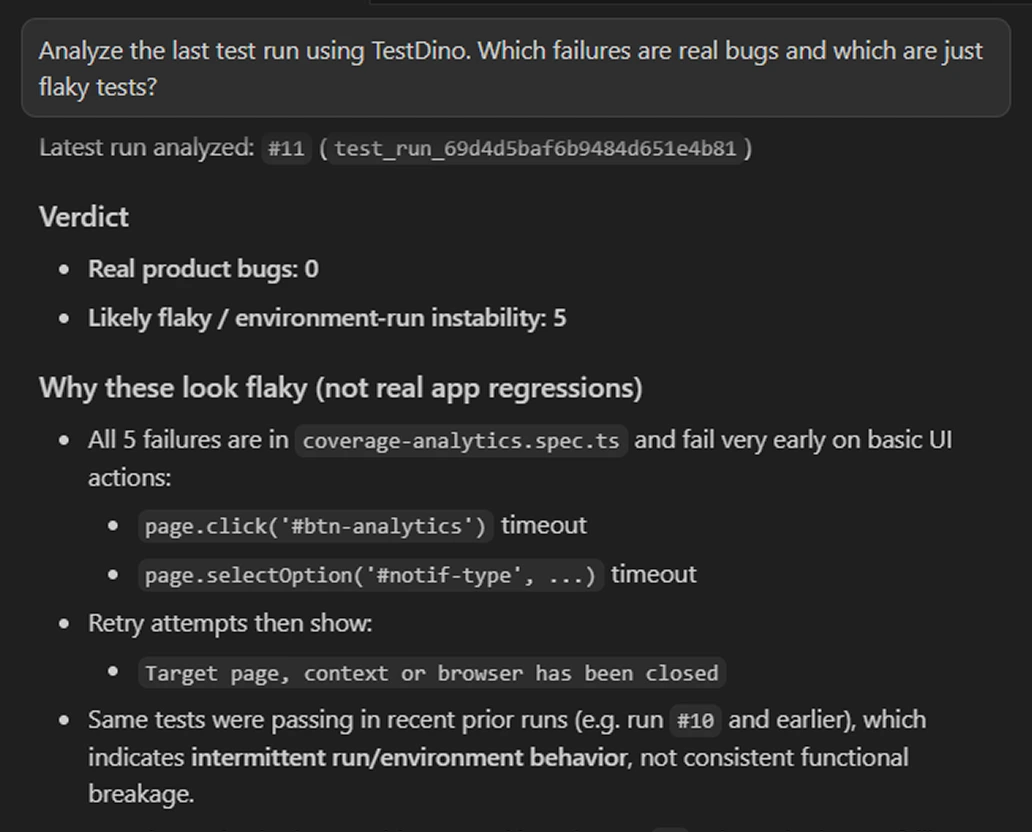
Let your AI agent fix flaky tests
Connect TestDino's MCP server to Cursor, Claude Code, or Copilot. Your AI agent finds the flakiest tests, looks at their failure history, and suggests targeted fixes without you switching to the dashboard.
Teams love what we built
See why developers choose TestDino to ship faster and debug smarter
We were on the default Playwright reporter, and it was tedious to dig through; half a day gone just triaging failures. The TestDino MCP changed that for us. I now run through the failures in minutes instead of devoting half a day to it, and pulling the latest runs straight through the MCP sped up bug triage drastically. AI failure classification and Slack reports do the rest. It's saved us weeks.
To triage failures, down from half a day
Saved across the team

Migrating to TestDino from Currents was an easy decision. The features are stronger, the cost is lower, and the interface makes debugging far less painful. Flaky test detection and AI failure classification have simplified debugging and reduced our CI costs by cutting down reruns and noisy failures.
Reduction in CI costs
Less time triaging failures

Over 30 flaky tests and no structured way to track them, just CI artifacts and morning guesswork. TestDino's "Most Flaky Tests" feature broke this pattern. We can see failure trends now and pull up video recordings of exactly what went wrong. The TestDino MCP server is the magic piece on top, I ask my Claude agent about a failure and it pulls full context from TestDino without switching tabs. We went from 30-something flaky tests down to 3 or 4.
Fewer flaky test reruns
Faster failure triage

Automated detection vs
manual flaky tracking
Automatic detection from retry data
Flaky tests identified automatically from retry data and cross-run patterns. No manual annotations needed.
Root cause classification
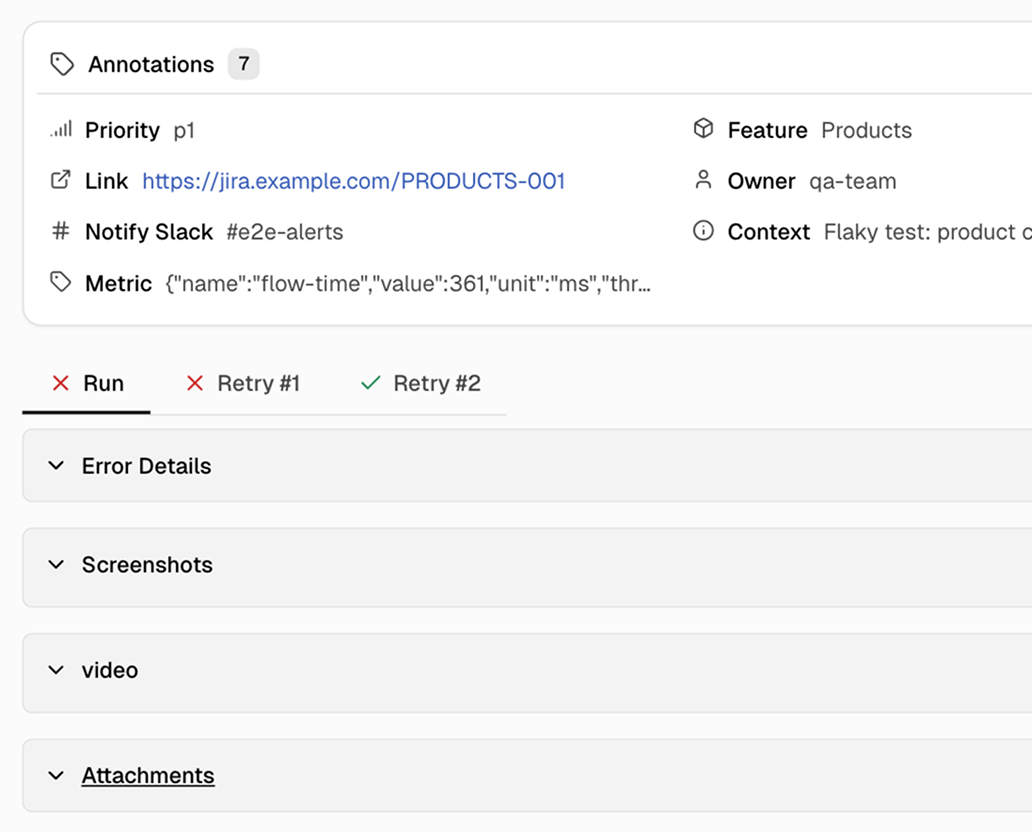
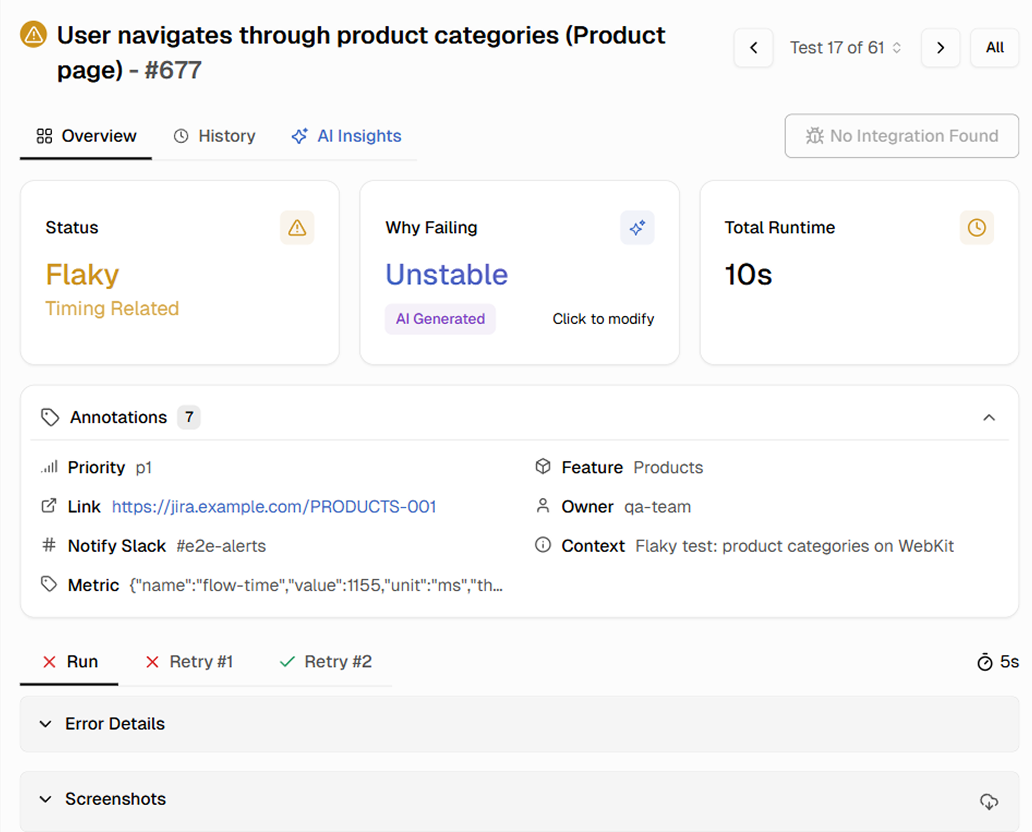
Each flaky test is classified into one of five categories: Timing Related, Environment Dependent, Network Dependent, Assertion Intermittent, or Other. A starting point for fixes.
Flaky rate tracking over time
After fixing a flaky test, track its stability across subsequent runs to confirm the fix held.
Prioritized flaky list by impact
Flaky tests ranked by frequency, wasted CI minutes, and pipeline blocks. Worst offenders surface first.
Cross-run pattern analysis
Tests that pass within a run but fail across runs are caught, covering both within-run and cross-run inconsistencies.
Team-wide flaky visibility
One shared dashboard so everyone sees the same flaky test data. New team members know what is unreliable from day one.
What you get with flaky detection
A complete view of every unreliable test with root cause classifications and stability trends.
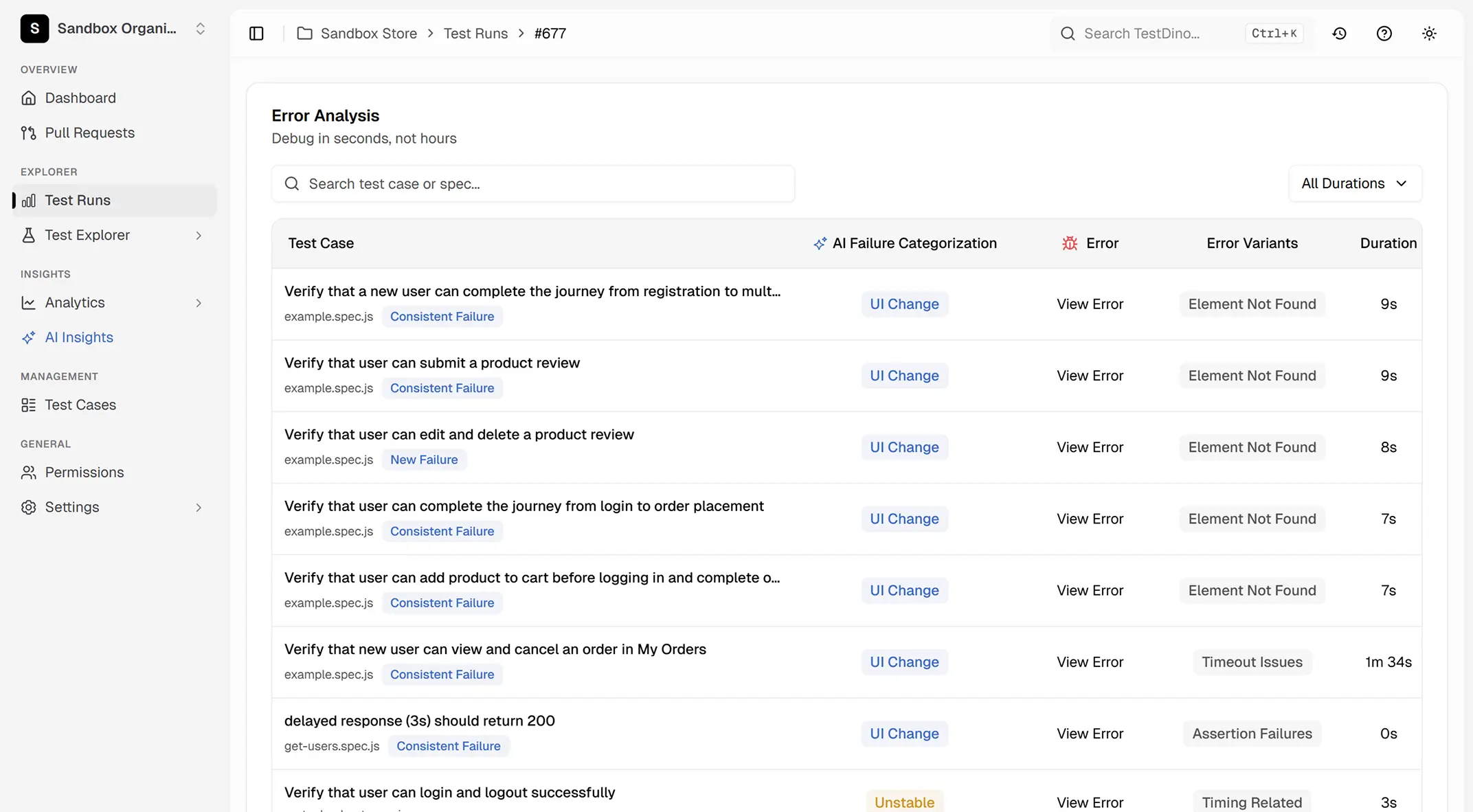
Root cause classification and failure grouping
Flaky tests are grouped by likely root cause. Timing-related flakes are separated from data dependency issues, which are separated from environment instability. This helps you batch similar fixes together instead of chasing individual failures.
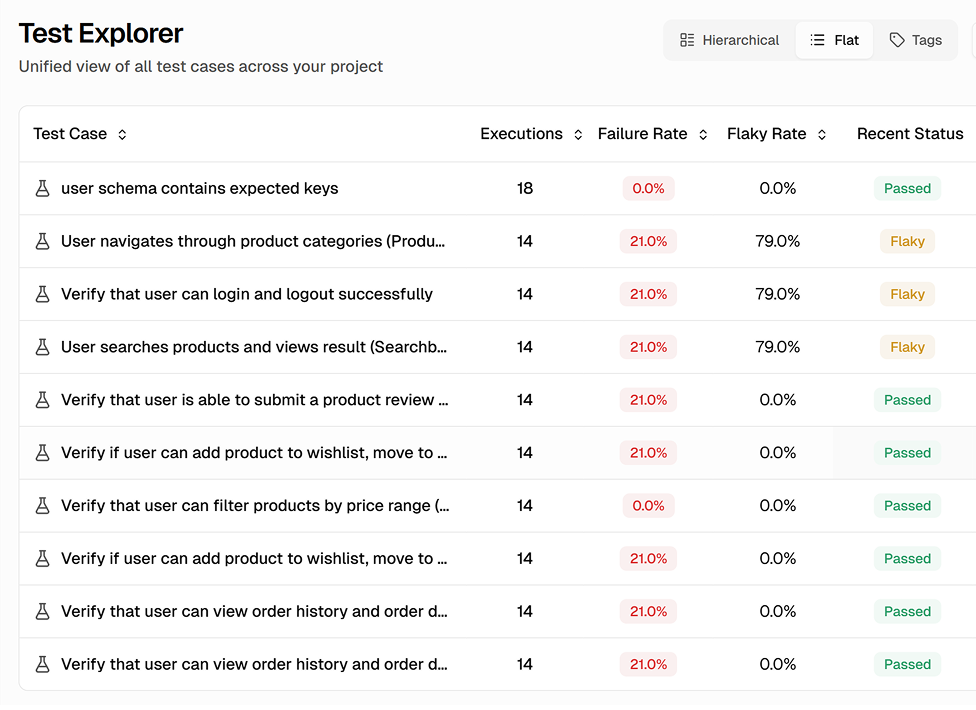
Automatic flaky test identification
Every test run is analyzed for retry patterns and cross-run inconsistencies. Tests that fail then pass on retry are flagged. Tests with different results across runs without code changes are flagged too. You get a complete, always-current list.
Stability trend tracking with flaky rate history
Every flaky test has a trend line showing its flaky rate over time. See whether a test is getting more unstable or stabilizing after a fix. Turn flaky management from reactive firefighting into measurable improvement.
Works with your favourite tools
Connect seamlessly with Jira, Slack, GitHub, Linear, Azure DevOps, Asana, and monday to keep your workflow smooth and your team aligned.
FAQs
TestDino uses two detection methods. Within-run retry analysis: if a test fails on one attempt and passes on a subsequent retry, it is flagged as flaky. Cross-run pattern analysis: if a test produces different results across runs without code changes, it is identified as flaky. Both work automatically from your first run.