OpenObserve Cut Playwright Flaky Tests by 90% with TestDino
OpenObserve scaled Playwright faster by cutting flaky tests from 30+ to just 3-4 with TestDino’s centralized CI insights and flaky test dashboard.

Introduction
OpenObserve builds an open source observability platform for logs, metrics, and traces. The product lives in the reliability space, so test stability affects release confidence directly.
The team runs Playwright in GitHub Actions. Default reporting worked at first. As the suite grew, the workflow broke down. Reports were slow to load.
Flaky tests climbed past 30. The team spent hours each day opening artifacts, comparing failures across branches, and rerunning tests without knowing if failures were real or noise.
OpenObserve needed reporting that scaled with test volume, tracked flaky tests systematically, and showed branch and environment context without manual work.
They adopted TestDino. Flaky tests dropped from 30 plus to 3 or 4. Daily debugging time dropped by hours. QA output improved.
This case study shows what changed and what the team uses today.
Company overview
OpenObserve is an open source observability platform used to monitor logs, metrics, and traces. The product sits in the reliability space, so internal release confidence matters. Fast, trusted CI feedback is a requirement.
Shrinath overview
Shrinath Rao is Lead Quality Assurance Engineer at OpenObserve, specializing in AI-first quality engineering and test automation.
He has over 7 years of experience in QA, with expertise in Playwright, Selenium, CI/CD pipelines, and autonomous testing systems.
OpenObserve’s Playwright testing setup
- Framework: Playwright
- CI: GitHub Actions
- Reporting: default Playwright report artifacts and links inside workflow run
 We ran tests in GitHub Actions and had to rely on artifact links to view reports.
We ran tests in GitHub Actions and had to rely on artifact links to view reports.


Key challenges faced by OpenObserve
The reporting layer stopped scaling as test volume, branches, and environments grew.
Four specific pain points emerged:
1. Limited visibility into failures
When a test run failed, the team struggled to answer basic questions:
- Is this failure new or repeating?
- Is this tied to a branch?
- Is this tied to an environment?
- Is this likely a flake or a real regression?
Without a stable view across runs, the team ended up doing manual triage.
We had no insights or dashboards. Every failure required manual investigation from scratch
2. Flaky tests with no tracking
Flaky tests increased, failures were harder to track, and the team had no systematic way to detect flakes, group them, and drive them down over time. Reruns and time spent interpreting red builds increased.
3. No branch and environment mapping
OpenObserve called out the lack of branch-level reporting and the difficulty of managing multi-branch results, plus the need to check stability across different environments.
We had no centralized reporting. Comparing results across branches and environments required manual work. Tracking which tests failed where, and whether failures were environment-specific or systemic, took significant time.
4. Slow triage and debugging
Reports were sometimes slow or unreliable to open. Artifact and storage issues made the click the link and debug flow inconsistent.
TestDino effect in OpenObserve’s workflow
What changed in practice:
1. One centralised dashboard for all Playwright runs
Instead of relying on CI links as the main UI, OpenObserve starts from a consolidated view of runs and failures.
2. Tracks flaky tests with screenshots, traces, and logs
Instead of treating flakiness as "this probably flakes," the team uses a dedicated flaky tests view to identify unstable tests and prioritize fixes.
Flaky tests. TestDino made it easy to find and fix them. 100% win.
3. Gets branch and environment mapping per execution
Branch and environment context help the team interpret failures faster and avoid manual sorting across multiple branch results.
4. Receives failures in Slack and GitHub
Notifications and checks point the team to the same reporting view, which reduces the amount of time spent jumping between tools.
5. Uses TestDino MCP for debugging
OpenObserve values being able to use TestDino MCP to help analyze failures using the reporting context already captured.
Where TestDino Helped
OpenObserve called out two signals:
1. Flaky test dashboard
This enabled the biggest measurable outcome. The team used flake visibility to stabilize tests consistently.
2. Ease of use in day to day debugging
OpenObserve highlighted the dashboard for flaky tests and the ease of use as the most impressive part.
Flaky test dashboard and easy to use experience is a game changer.
Supporting signal and workflow integration
- PR level visibility through GitHub
- Branch and environment mapping for stability comparisons
- Slack notifications for faster awareness
- MCP-based analysis for faster interpretation
Results after adopting TestDino
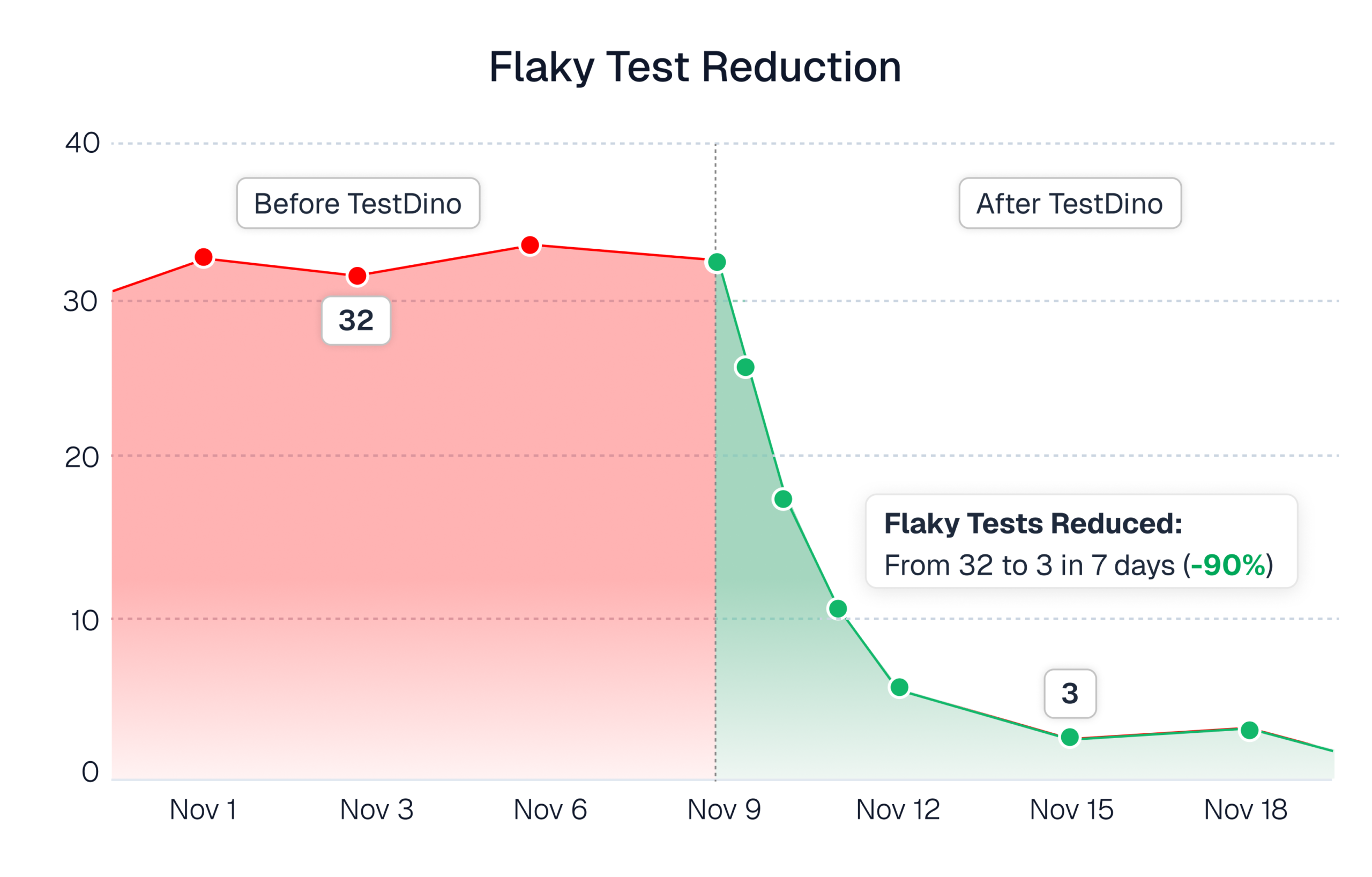
1. Flaky tests reduced from 30 plus to 3 or 4
OpenObserve reduced flaky tests from 30 plus down to 3 or 4 after adopting TestDino and using the flaky test dashboard to drive stabilization work.
Within a very short period, we have stabilized a lot of test cases. In fact, we have reduced the flaky test cases down to three from 30+.
2. Daily triage and debugging time dropped by hours
TestDino saves a few hours every day by reducing manual analysis and making failures easier to understand and act on.
We are saving a few hours every day. I can't imagine my work without TestDino!
3. QA output improved
OpenObserve did not tie TestDino directly to release frequency with a measurable number, but reported that QA deliverables got better as stability improved.
Our QA deliverables have gotten so better now, and stakeholders have clarity on e2e test suite/runs.
4. AI native approach by TestDino
Measurable Improvements After Adopting TestDino
| Feature / Metric | Before TestDino | After TestDino |
|---|---|---|
| Flaky Test Count | 30+ flaky tests (untracked) | 90% Reduction in flaky tests (3 to 4) |
| Triage & Debugging | Manual “artifact hunting” (unzipping traces/logs) | Dashboard-first triage (instant visibility) |
| Daily Time Lost | Several hours spent on manual analysis | Saved hours every day |
| Visibility | Limited; hard to track repeating failures | Full history with dedicated flake tracking |
| Context Switching | Juggling between GHA links and local files | Slack & GitHub integration (centralized view) |
| Environment Mapping | No clear way to track stability per env | Automatic branch & environment mapping |
| QA Output | Struggled to keep up with test volume | Measurable improvement in deliverables |
What would regress if TestDino were removed
OpenObserve would lose two things
- Controlling flakiness: Without a flaky test view and history, flaky tests become harder to detect and harder to drive down.
- Reducing manual CI investigation: Without centralized reporting, the team would return to opening artifacts and links, then manually correlating failures across runs, branches, and environments.
TestDino is now part of how the team maintains stability and keeps CI feedback usable.
Who benefits most at OpenObserve
- QA: QA uses TestDino for flake control, day to day triage, and stability tracking across branches and environments.
- Engineers reviewing PRs: GitHub and PR visibility makes understanding failures easier without digging through artifacts.
- Anyone responsible for CI reliability: Branch and environment mapping, plus failure context, helps reduce wasted reruns and repeated manual investigation.
Final takeaways
OpenObserve reduced flaky Playwright tests and saved hours every day in CI triage and debugging.
Three things matter for teams scaling Playwright suites:
Track flaky tests systematically
OpenObserve used the flaky test dashboard to identify unstable tests and prioritize fixes. Flake detection became a process backed by history and trends instead of guesswork.
Centralize reporting to remove manual steps.
Without TestDino, the team would return to downloading artifacts and correlating failures manually. Dashboards with GitHub and Slack integration made failures visible immediately and eliminated context switching.
Use branch and environment mapping to debug faster
Branch and environment mapping helped the team understand if failures were isolated or systemic. Multi-branch results became easier to interpret without manual sorting.
Setup took some effort, but did not require rebuilding CI. The team integrated GitHub, Slack, and TestDino MCP while keeping the same execution flow.
TestDino solved the scaling problem that the default reporting created. The platform is now part of how OpenObserve maintains stability and keeps CI feedback usable.
Shrinath recently shared his approach on e2e
Shrinath Rao shared how he built an autonomous QA team using AI agents at OpenObserve.
Results
- Feature analysis: 60 min to 5 min
- Flaky tests reduced by 85%
- Test coverage: 380 to 700+ tests
- Caught a production bug before customer reports
Approach
6 specialized AI agents (Analyst, Architect, Engineer, Sentinel, Healer, Scribe) handle test creation, execution, healing, and documentation for TestDino autonomously.

Pratik Patel
Co-founder



