

Flaky Tests: The Complete Guide to Detection & Prevention
Find top Playwright tutorials, documentation, tools, and guides in one place to learn automation, testing patterns, and CI/CD workflows.






Same code. Same environment. Different result.
In CI/CD, this is the definition of a flaky test. It is the single biggest obstacle to a fast, reliable release cycle.
Consider the scale of the problem:
-
Google found that 84% of pass-to-fail transitions in their CI involved a flaky test, not a real bug.
-
Atlassian loses thousands of developer hours a year to "retry" culture.
- The Reality: Fixing tests one-by-one is a losing game. At Google, new flakes appear at roughly the same rate they fix old ones.
To solve flakiness, you have to stop treating it as a bug and start treating it as a systemic health issue. This guide provides a roadmap based on research from 51 major open-source projects and a 4-pillar framework we use to organize what teams at Google, Slack, and Atlassian have built internally.
What is a flaky test?
A flaky test is a software test that produces both passing and failing results on the same code, commit, and environment — without any changes. Also called non-deterministic or intermittent test failures, flaky tests are the leading cause of unreliable CI/CD pipelines.
Flaky tests break trust in both directions. A flake to red wastes time investigating a non-bug. A flake to green lets a real bug slip through. Most people only worry about the first kind. The second is worse.
The cost of flaky tests
-
Google (2016): 84% of pass-to-fail transitions are flaky, not real bugs. 16% of all tests have some flakiness. (Google Testing Blog)
-
Atlassian (2025): 150,000 developer hours per year wasted on flaky tests. (Atlassian Engineering)
-
Slack (2022): 57% of build failures were caused by test job failures (flaky + genuinely failing tests). After automated detection and suppression, test job failure rate dropped to under 4%. (Slack Engineering)
Quick math for your team: An industrial case study (Leinen et al., ICST 2024) found that a team of ~30 developers spent 2.5% of their productive time dealing with flaky tests, including 1.3% on repairs alone. Your number will vary. Track it: flaky_tests x avg_investigation_minutes x developer_hourly_rate x frequency.
Fowler's 2011 essay identified most of these patterns early. A University of Illinois study (Luo et al., FSE 2014) analyzed 201 flaky-test fixes across 51 open-source projects and found recurring causes such as async waits, concurrency, and test order dependency. Those findings map well to these 6 buckets:
| Category | Summary | What helps |
|---|---|---|
| Timing | Bare sleeps, missing waits, race conditions | Event-driven waits (Playwright auto-waiting; see framework fixes for Cypress and Selenium) |
| Shared state | Tests depend on each other's data or run order | Each test owns its state: fresh browser contexts, isolated setup/teardown |
| Environment | CI vs local differences, non-deterministic environments, resource starvation | Deterministic environments, proper CI resources, capped parallel workers |
| External deps | Remote services, 3rd-party APIs, rate limiting | Mock at the network layer (Playwright, Cypress intercept, WireMock) |
| Resource leaks | Unclosed connections, memory, file handles | Set pools to size 1 (Fowler, 2011); track duration drift |
| Non-determinism | Time zones, random values, date-sensitive logic | Freeze clock (Playwright, Cypress clock, Sinon); seed random values |
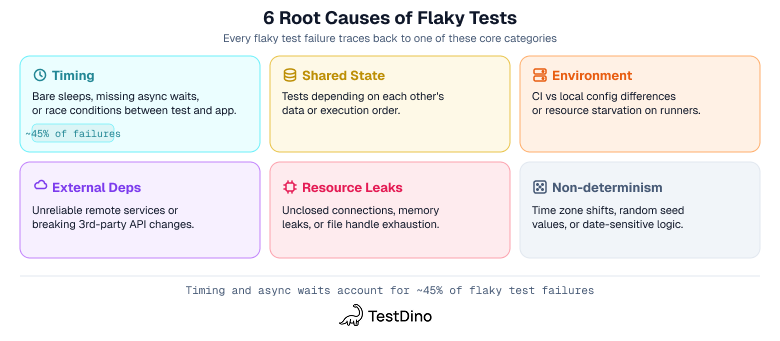
Timing and async coordination issues show up repeatedly in both research and engineering write-ups. An ICSE 2021 study of UI flaky tests found that async-wait subcategories accounted for roughly 45% of UI-specific flaky tests (106 of 235 studied). The pattern is consistent across frameworks. Here is the fix:
// Brittle - fixed wait guesses when the app will be ready
await page.getByRole('button', { name: 'Submit' }).click();
await page.waitForTimeout(2000);
await expect(page.getByText('Ticket submitted')).toBeVisible();
// Better - wait for the real user-visible outcome
await page.getByRole('button', { name: 'Submit' }).click();
await expect(page.getByText('Ticket submitted')).toBeVisible();

Tip: Tests pass with --workers=1 but fail with --workers=4? Shared state is a strong suspect. Google (2017) found flakiness rose sharply with test size: about 0.5% for small tests vs. 14% for large tests.
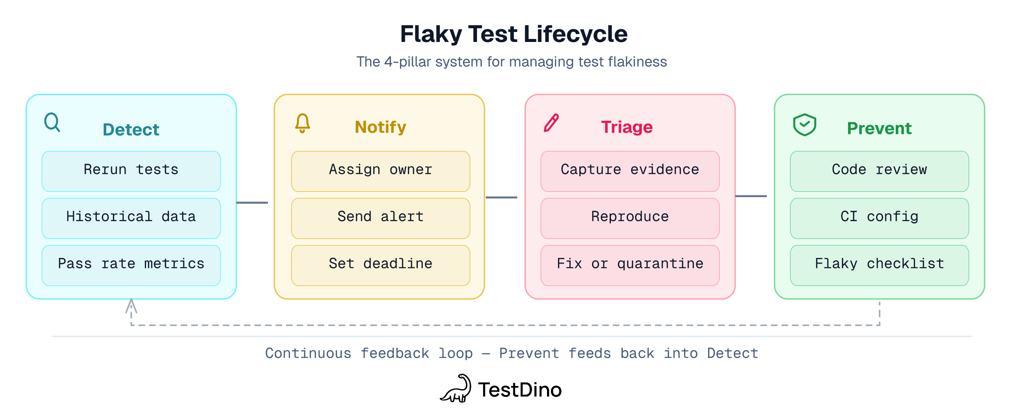
How to detect flaky tests
You can't fix what you can't measure. This pillar turns "we have some flaky tests" into "here are the tests causing most of our CI disruption."
1. Rerun-based detection
Run the same test multiple times on the same commit. If a test fails then passes without code changes, it's flaky.
For detection, use repeat/rerun modes: Playwright --repeat-each, pytest pytest-repeat, or loop scripts. This is different from automatic retries (Playwright --retries, Jest jest.retryTimes(), Cypress retries), which re-run failures to get a green build. Retries keep CI moving but mask flakiness. Use repeat-runs to detect, retries to unblock.
Limitation: rerun-based detection only catches high-frequency flakes. A test that flakes 1-in-300 runs won't show up in 10 reruns. That's where heuristic-based detection and historical cross-run analysis pay off. For a more advanced approach, DeFlaker (Bell et al., ICSE 2018) detects flaky tests without rerunning them by tracking which code a test actually covers and comparing against recent changes.
2. Historical analysis and metrics
Per-test flakiness scores over a rolling window give you a much clearer picture than any single run. Here's a minimal data model (from Reddit Engineering's FTQS):
| Column | Example |
|---|---|
| test_name | checkout.spec.ts > guest pays by card |
| status | pass, fail, flaky |
| commit_sha | a1b2c3d |
| branch | main |
| duration_ms | 4230 |
| runner_id | runner-3 |
| timestamp | 2026-03-15T08:12:00Z |
With this data, find your worst offenders: any test where (fail_count / total_runs) > 0.02 over the last 14 days. A data-driven QA approach turns this raw data into prioritized action items.
Thresholds: a practical starting point is to investigate anything above 2% over a rolling window. Google reported roughly 1.5% overall flakiness and still considered it a drag. Many teams escalate hard once a test reaches the mid-single digits.
Flaky test metrics to track: flaky rate (% needing retries), MTTR (detection to fix), duration trends (tests getting slower = likely leak), environment correlation (failures tied to specific runners/shards).
Build your own (Atlassian built Flakinator, Reddit piped SQL into JIRA), or use tools like TestDino that track this out of the box. TestDino's flaky detection calculates a stability percentage per test and categorizes root causes automatically. It also sends scheduled PDF reports with pass rates, failure trends, and flaky test lists.
If you only do 1 thing from this section: track per-test pass rates over a rolling 14-day window. Even a spreadsheet works.
How to assign ownership and notify the right people
Detection without notification is a dashboard nobody checks.
1. Define test ownership in code
Tests without owners get ignored. The fix: put ownership where developers already look - in the test file itself.
The simplest approach works for any framework: a CODEOWNERS file or a test-owners.yaml mapping tests/payments/ to team-payments. When a test starts flaking, ownership is already clear.
In Playwright, you can go further with per-test annotations that tag each test with an owner, priority, and notification target:
test('guest checkout completes with valid card', {
annotation: [
{ type: 'owner', description: '@sarah' },
{ type: 'ticket', description: 'TA-242' },
{ type: 'docs', description: 'docs.abx.com/guest' },
],
}, async ({ page }) => {
// test body
});
TestDino reads these annotations and routes alerts automatically - when this test fails, @sarah gets a Slack message in #checkout-alerts with the failure context.
SLA example (adapt to your team):
-
Flaky test detected: owner notified within 10 minutes
-
Owner triages within 2 working days
-
Critical-path flakes (p0/p1): fixed or quarantined within 5 working days
Note: Assign a person, not "the team." Without a named owner with a deadline, quarantine becomes permanent.
2. Set up automated alerts
A good alert includes: test name, flakiness rate, link to the failing run, and a suggested cause. The anti-pattern is silent retry - a test quietly passes on attempt 2 and nobody knows it flaked.
One routing rule that saves time: scattered failures across different tests = test flakiness (route to the test owner). A wall of failures across all tests = infrastructure (route to DevOps).
TestDino's AI failure analysis adds root cause context by classifying each failure as Actual Bug, UI Change, Unstable Test, or Miscellaneous and grouping by cause bucket (Timing Related, Environment Dependent, Network Dependent, Assertion Intermittent). The evidence panel attaches screenshots, video, traces, console logs, and error details per attempt.
3. Surface flakiness in pull requests
The best place to catch flakiness is before merge. Block or warn on PRs that touch historically flaky tests - even a simple CI step that checks recent flake rates and posts a comment gives reviewers context.
TestDino's GitHub integration does this automatically: it attaches test summaries to PRs with links to the dashboard for traces and root cause details. Status Checks enforce merge gates with a configurable pass rate threshold and mandatory tags (e.g., @critical, @payment). 2 modes:
-
Strict: flaky tests count as failures. Use on production branches
-
Neutral (default): flaky tests excluded from pass rate, so known flakes don't block merges while you fix them
The 3 most common mistakes in flaky test management
Before the debugging workflow, here are the 3 patterns that keep teams stuck:
- Treating retries as a fix. Retries keep CI green but hide the problem. Teams that rely on retries alone see flakiness grow because nobody investigates the root cause. Use retries to unblock, not to close the ticket.
- No owner, no deadline. A flaky test without a named owner and a fix-by date will sit in quarantine forever. Atlassian, Reddit, and Slack all built ownership routing and ticketing into their flaky-test workflows, and each credited it as a key factor in driving resolution rates.
- Ignoring CI resource limits. A test that passes on your 16GB laptop but fails on a 4GB CI runner isn't flaky, it's resource-starved. Before blaming the test, check whether the environment can actually support it.
How to fix flaky tests step by step

This is the section most developers want to jump straight to. But triage only works when you know which tests to fix (detection) and someone is accountable (ownership).
1. Capture evidence and reproduce
When a flaky failure happens, you need 2 things: artifacts from the failure, and a way to reproduce it.
Artifacts to capture on every CI failure (configure this once):
-
Traces: Playwright trace viewer, Cypress time-travel, Selenium logging
-
Screenshots and video from the failing run
-
Console/browser logs, network logs / HAR files
-
Infrastructure context: worker, shard, runner, browser, OS, headless/headed
-
Git context: commit SHA, branch, test seed/order
Reproduce with retries off:
-
--retries=0 (or equivalent)
-
Run the test alone 20-50 times. Always passes? The problem is likely interaction with other tests
-
Run with 1 worker, then increase. Fails only in parallel? Shared state or resource contention
-
Run the exact failing commit, not latest main
Tip: If the test flakes rarely, 20 runs won't catch it. Kinaxis reported tests that failed once in every 300,000 runs. For low-frequency flakes, run 100+ times or rely on historical analysis instead.
2. Narrow down the root cause
Compare local vs CI conditions. Your machine has more CPU, RAM, and faster disk. Our guide to debugging Playwright tests covers this comparison in detail.
-
Only fails in CI? Likely environment. Reproduce with Docker: docker run --cpus=2 --memory=4g
-
Only on 1 shard or runner? Under-provisioned
-
Only under parallel load? Shared state or resource contention
-
Only on 1 browser or headless mode? Browser-specific behavior
-
Only at certain times of day? Timezone logic or shared infrastructure load
Once you have a theory, stress it:
-
Timing? Add network latency with tc (Linux) or Clumsy (Windows)
-
Shared state? Randomize test order, run with maximum parallelism
-
Resources? Constrain: docker run --cpus=1 --memory=2g
-
Non-determinism? TZ=America/Los_Angeles, different locales, different dates
-
External dependency? Inject mock failures: slow responses, 500 errors, timeouts
3. Apply the fix and verify
Match evidence to a root cause:
| If the evidence points to... | The fix is... |
|---|---|
| Bare sleeps or timeouts | Replace with event-driven waits (auto-waiting) |
| Shared state between tests | Isolate each test: own state, own setup, own teardown |
| CI-only failures | Match CI resources locally with Docker |
| External API flakiness | Mock at the network layer; contract tests to keep mocks honest |
| Gradually increasing failures | Resource leak. Set pools to size 1, track duration drift |
| Timezone or random-value sensitivity | Freeze clock, seed random values |
Do not stop at a retry or a longer timeout. Use them only as temporary containment while you fix the actual cause. Then verify: run the test 50+ times locally and in CI before closing.
Illustrative example: timing flake
// BEFORE: fixed wait guesses at backend timing
test('submits support ticket', async ({ page }) => {
await page.goto('/support');
await page.fill('#message', 'Help!');
await page.getByRole('button', { name: 'Submit' }).click();
await page.waitForTimeout(2000);
await expect(page.locator('.success')).toBeVisible(); // fails when response > 2s
});
// AFTER: wait for the actual response, not a guess
test('submits support ticket and sees confirmation', async ({ page }) => {
await page.goto('/support');
await page.getByLabel('Message').fill('Help!');
await page.getByRole('button', { name: 'Submit' }).click();
await expect(page.getByText('Ticket submitted')).toBeVisible({ timeout: 10000 });
});
A representative investigation looks like this: repeated CI runs fail at the .success assertion on slower runners. The waitForTimeout(2000) guesses at backend timing, so it breaks under resource contention. Replace the guess with an assertion on the real success state.
Google's research team built on this approach at scale: their root cause localization tool (IEEE ICSME 2020) automatically pinpoints the code responsible for flaky behavior. Apple took a different angle with test repetition modes in Xcode (WWDC 2021), letting you run tests in retry-until-failure or retry-until-success loops to surface flakes before shipping.

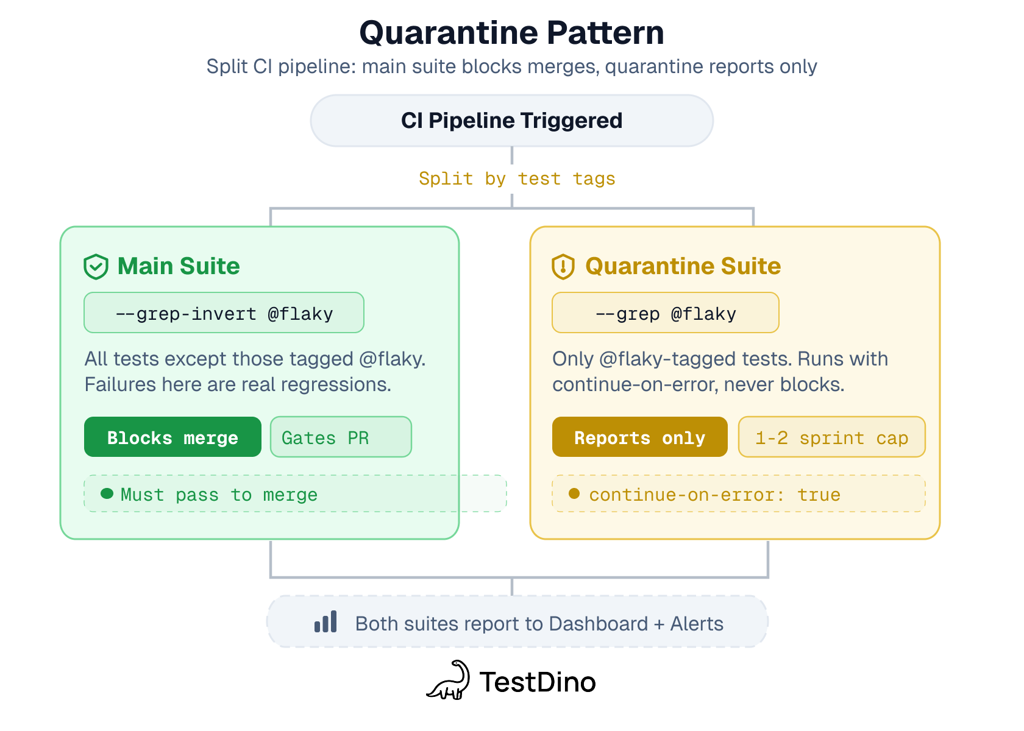
4. Quarantine while you fix
The 6 root causes of flaky tests: timing, shared state, environment, external dependencies, resource leaks, and non-determinism
Tag the flaky test, move it to a separate non-blocking CI job, fix it within a deadline.
Teams usually pick one of three strategies. Here's how they compare:
| Strategy | What happens | Keeps coverage? | Fixes root cause? | Best for |
|---|---|---|---|---|
| Retry | Re-run on failure, pass on 2nd attempt | Yes | No (masks the problem) | Unblocking CI while you investigate |
| Quarantine | Move to non-blocking job, track with deadline | Yes | Eventually (if deadline enforced) | Tests you plan to fix within 1-2 sprints |
| Delete | Remove the test entirely | No | N/A | Tests that are unfixable or no longer relevant |
test('inventory sync after bulk upload', {
tag: ['@flaky'],
annotation: [
{ type: 'testdino:flaky-reason', description: 'Redis cache race condition on parallel writes' },
{ type: 'testdino:owner', description: '@mike' },
],
}, async ({ page }) => {
// test body
});
# Main suite - blocks merge
- name: Run tests
run: npx playwright test --grep-invert @flaky
# Quarantine suite - runs but doesn't block
- name: Run quarantined tests
run: npx playwright test --grep @flaky
continue-on-error: true
Quarantine policy (adapt to your team):
-
Cap: no more than 5% of your suite in quarantine
-
Time limit: 1-2 sprints
-
Not fixed by the deadline? Fix it or delete it. Quarantine without a deadline is just deletion with extra steps
If you only do 1 thing from this section: configure CI to save artifacts (traces, screenshots, logs) on every failure. That alone usually shortens debugging time substantially.
How to prevent flaky tests from reaching CI
New flaky tests appear at roughly the same rate you fix old ones. Prevention is the only way to bend that curve.
1. Code review checklist
Add this to your PR template. Reviewers check each item on any PR that adds or modifies tests:
-
Shared state? Isolate it
-
Bare sleep() or fixed waits? Use event-driven waits
-
Teardown guaranteed on failure? Use try/finally or framework hooks
-
Test order dependency? Randomize and verify
-
Unmocked external services? Mock non-critical deps
-
Non-deterministic assertions? (Random data, timestamps, UUIDs)
-
Works with reduced CPU/RAM? Think CI constraints
-
Could this test be smaller? Push it down the testing pyramid: unit over integration over E2E
For a more complete version, see our Playwright automation checklist.
If your team uses AI to generate tests, the same checklist applies. AI-written Playwright tests can introduce flaky patterns (bare waits, shared state) just as easily as hand-written ones, so review them with the same rigor.
Team agreement (paste into your wiki): "We don't merge tests that use bare sleeps, global mutable state, or unmocked external services. Flaky tests are either fixed within 2 sprints or quarantined with a named owner and removal date."
2. Write tests for diagnosability
Write every test as if someone will debug it from a single failed CI run, without rerunning it. Using structured Playwright test scripts with the Page Object Model helps keep tests consistent and easier to triage.
-
Precise name: not checkout works, but guest user can pay by card and sees order confirmation
-
Labeled steps: Playwright test.step(), Cypress custom commands. When a test with 8 steps fails at step 5, you skip 4 steps of investigation
-
Logged context: user ID, order ID, seed value. If data is random, log the seed
-
Precise assertions: assert the specific element or status code, not just "page loaded." Playwright assertions, Cypress assertions, Selenium locators
Example: a diagnosable test vs a black-box test
// Hard to debug - no steps, vague name, no context on failure
test('checkout works', async ({ page }) => {
await page.goto('/products');
await page.click('.add-to-cart');
await page.click('.checkout');
await page.fill('#card', '4242424242424242');
await page.click('#pay');
await expect(page.locator('.confirmation')).toBeVisible();
});
// Easy to debug - labeled steps, precise name, logged context
test('guest user can pay by card and sees order confirmation', async ({ page }) => {
await test.step('add product to cart', async () => {
await page.goto('/products');
await page.getByRole('button', { name: 'Add to cart' }).click();
});
await test.step('complete checkout with card payment', async () => {
await page.getByRole('link', { name: 'Checkout' }).click();
await page.getByLabel('Card number').fill('4242424242424242');
console.log(`Checkout at ${new Date().toISOString()}, URL: ${page.url()}`);
await page.getByRole('button', { name: 'Pay' }).click();
});
await test.step('verify order confirmation', async () => {
await expect(page.getByText('Order confirmed')).toBeVisible();
});
});
When the second test fails at "complete checkout with card payment," you know exactly where to look. The first just says "locator '.confirmation' not found" with no indication which step broke.
2 rules that get broken constantly:
-
Don't let cleanup destroy evidence. If a test fails, keep artifacts and state. Clean up on the next run's setup, not the failed run's teardown
-
Don't use silent retries as your only safety net. A retry that passes hides the first failure, which has the useful information
3. CI configuration that reduces flakiness
-
Allocate enough CPU and RAM per runner. Under-provisioned runners are a common source of intermittent failures
-
Shard tests across multiple CI jobs instead of cramming workers into 1 runner
-
Use retry-on-fail with quarantine tracking, not silent retry
-
Add a smoke test that checks database, permissions, and connectivity before the full suite. Fail fast with 5 tests, not 2,000 timeouts
If you only do 1 thing from this section: add the code review checklist to your PR template. It costs nothing and catches the most common patterns.
Framework-specific fixes for flaky tests
Flaky tests in Playwright
-
Enable traces on first retry. Set trace: 'on-first-retry' in your Playwright config. When a test flakes, you get a full trace without the storage cost of tracing every run. See our trace viewer guide for setup
-
Prefer semantic locators. page.getByRole() and page.getByLabel() are usually more resilient than brittle CSS chains because they target user-facing structure. Playwright still runs actionability checks before clicking either way. More in our locators guide
-
Lean on built-in isolation. Playwright creates a fresh BrowserContext per test, so cookies and storage do not leak between tests unless you explicitly opt into reuse
For more, see Playwright flaky tests: how to find and fix them.
Flaky tests in Cypress
-
Use cy.intercept() for network control. Mock unstable APIs at the network layer instead of hitting real services. This removes a common source of external-dependency flakes
-
Enable test isolation. Cypress 12+ has test isolation on by default, clearing cookies and storage between tests. Make sure it's not disabled in your config
-
Avoid cy.wait(ms). Use cy.intercept() with cy.wait('@alias') to wait for specific network responses instead of guessing with fixed timeouts
Flaky tests in Selenium
-
Use explicit waits, not implicit. WebDriverWait with ExpectedConditions targets the specific element you need. Implicit waits apply globally and mask timing problems
-
Isolate browser state. Create a fresh WebDriver session per test or clear cookies/storage in setup. Selenium doesn't do this automatically like Playwright does
-
Make browser mode explicit in CI. Use a consistent headless setup or a consistent virtual display setup so you are not debugging environment drift between local and CI
Flaky tests in pytest
-
Use pytest-randomly to catch order dependencies. Shuffles test order on every run. If tests pass in sequence but fail when randomized, you have shared state. Pin a seed to reproduce: pytest --randomly-seed=12345
-
Reset database state between tests. Use pytest-django fixtures/marks or your own rollback/reset fixtures so each test starts clean. Shared database state is a common source of backend flakiness
-
Freeze time with freezegun. freezegun or time-machine eliminates date/timezone flakes. Faster than mocking datetime manually and works across imports
Flaky tests in JUnit
-
Use @RepeatedTest to surface flakes early. JUnit 5's @RepeatedTest(50) runs a test N times in a single invocation. Add this to suspect tests before promoting to CI
-
Isolate with @TestInstance(Lifecycle.PER_METHOD). This is the JUnit 5 default, but some codebases override it to PER_CLASS for performance. PER_CLASS shares state across tests in the same class and can create ordering flakes
-
Use Testcontainers for disposable infrastructure. Testcontainers gives you fresh Dockerized dependencies for the test scope you choose, which reduces shared-infrastructure flakes in integration suites
Flaky test management tools
You can manage flaky tests with custom scripts, open-source tooling, or a dedicated platform. Here's how the options compare:
| Approach | Examples | Strengths | Limitations |
|---|---|---|---|
| Custom scripts + SQL | Bash loops, BigQuery, Grafana dashboards | Full control, no vendor lock-in | You build and maintain everything: ingestion, UI, alerts, reports |
| CI-native features | GitHub Actions retry, GitLab CI retry:, Jenkins Flaky Test Handler | Zero setup, works inside your existing pipeline | Mostly retry-oriented. Historical tracking, ownership routing, and root cause analysis usually require extra tooling |
| Open-source frameworks | Allure, ReportPortal | Rich reporting, community plugins | Self-hosted infrastructure. Flaky detection is manual or limited |
| Dedicated platforms |
TestDino, Datadog CI Visibility, BrowserStack Test Observability, Trunk Flaky Tests |
Automated detection, AI classification, ownership routing, merge gates | SaaS cost. Varying levels of framework support |
The right choice depends on your team size and how much infrastructure you want to own. Small teams can start with CI-native retries and a spreadsheet. Once you're tracking 500+ tests across multiple pipelines, a dedicated platform saves more engineering time than it costs.
Enterprise case studies
| Team | What they did | Result |
|---|---|---|
| Auto-detection + suppression at scale | 57% to under 4% test-job failure rate | |
| 3-scenario retry + impact scoring | 18x reduction in flaky failures | |
| Flakinator: detection + auto-ownership | Recovered 22,000+ builds | |
| FTQS: quarantine + ownership workflow | Separated flaky-test noise from blocking CI | |
| Simple visibility dashboard | 33% reduction in 2 months |
More: Meta, Airtable, Uber, Kinaxis have all published similar playbooks. See also how OpenObserve reduced flaky tests by 90% after centralizing test reporting.
How flaky tests affect developer experience
The cost of flaky tests goes beyond CI minutes. Test execution flakiness erodes the feedback loop that makes CI/CD valuable, and becomes a CI/CD pipeline bottleneck that slows down the entire engineering organization.
-
Trust decay: When tests cry wolf, developers stop trusting CI. They merge with failing checks, skip test runs locally, and treat red builds as noise. Once that habit sets in, real bugs slip through
-
Context switching: A flaky failure pulls a developer out of their current task to investigate something that turns out to be nothing. That context switch costs 23 minutes on average to recover from
-
Slow merges: Teams with high flakiness add manual "re-run CI" steps to their merge process. This adds 15-30 minutes of idle waiting per PR, multiplied across every developer, every day
-
Onboarding friction: New team members can't tell which failures are real and which are "just that flaky test." They either waste time investigating known flakes or learn to ignore CI too early
Spotify found that simply making flakiness visible on a dashboard reduced it by 33% in 2 months (from 6% to 4%). They did not attribute the improvement to any single technical change, which suggests that visibility itself was a major factor. Setting up proper Playwright reporting makes that visibility automatic.
Conclusion
Flaky tests are expensive and pervasive. Google reported that 84% of pass-to-fail transitions were flaky, not real regressions.
-
The 4 pillars (Detect, Notify, Triage, Prevent) only work as an ongoing system, not a one-time cleanup.
-
Visibility alone drives reduction. Spotify got 33% from a dashboard.
-
Assign owners with deadlines. Without a named person, nothing gets fixed.
-
Prevention compounds. Fixing is linear, preventing is exponential.
Your next step: open your CI dashboard, find the test with the highest failure count, and run it through the debugging workflow. Document the process as you go - that document becomes your team's flaky test runbook.
FAQ
A flaky test is a test that passes and fails on the same code without any changes. Run it twice on the same commit and get different results. A common cause is timing: the test assumes something will be ready in X milliseconds, and sometimes it is not. Google found 84% of pass-to-fail transitions were flaky, not real bugs.
A flaky test produces different results on the same code. An intermittent bug is a real defect that only shows under certain conditions. Flaky tests need test-level fixes (waits, isolation, mocking); intermittent bugs need product-level fixes. TestDino's AI classification sorts failures into Actual Bug vs Unstable Test to help tell them apart.
The top 3 causes are: 1) async wait/timing issues, 2) concurrency and shared state, and 3) test order dependency. This comes from a University of Illinois analysis of 201 flaky test fixes across 51 open-source projects. An ICSE 2021 study found that async-wait issues accounted for roughly 45% of UI-specific flaky tests. The fix for timing is almost always the same: replace fixed waits with event-driven waits. For a full overview of the research, see Parry et al.'s survey of flaky tests (ACM TOSEM). See common causes for framework-specific links.
Table of content
Flaky tests killing your velocity?
TestDino auto-detects flakiness, categorizes root causes, tracks patterns over time.
Follow Us






