Rerun only what failed, not the entire suite.
Run tdpw cache after your test step, then tdpw last-failed in your retry condition. Your retry step gets exactly which tests to rerun, per shard and per branch.

Full suite reruns are killing
your pipeline and budget
One flaky test fails and CI reruns the entire suite. 45 minutes wasted, every PR, every day.

You are paying for tests that already passed
Every full rerun re-executes hundreds of tests that succeeded. Teams running 10+ retries a day waste 6-8 hours of CI compute doing nothing useful.
Sharded runs make selective retries nearly impossible
When your suite splits across 4 or 8 shards, figuring out which shard held the failing test is a manual scavenger hunt. Most teams rerun all shards because it is easier.
Branch-specific failures get lost in the noise
A test failing on your feature branch might pass on main. Without branch-aware tracking, you cannot tell if the failure is your code or pre-existing, so you rerun everything.
Flaky tests trigger unnecessary full reruns
That intermittently failing test triggers a full pipeline retry every time. Your team knows it is flaky but CI does not, so it burns another 45 minutes proving what everyone suspected.
10 tests failed. CI re-ran all 100 again.
Full suite rerun
Smart failed rerun
How selective reruns work
Two CLI commands handle everything. No changes to your test files, no custom scripts.
Add the TestDino reporter
One line in your Playwright config. TestDino captures every pass, fail, skip, and flaky result with full shard and branch metadata on each CI run.

reporter: [ ['html', { outputDir: './playwright-report' }], ['json', { outputFile: './playwright-report/report.json' }], ]
npx tdpw upload <report-dir> --token=$TESTDINO_API_KEY
Cache results after each run
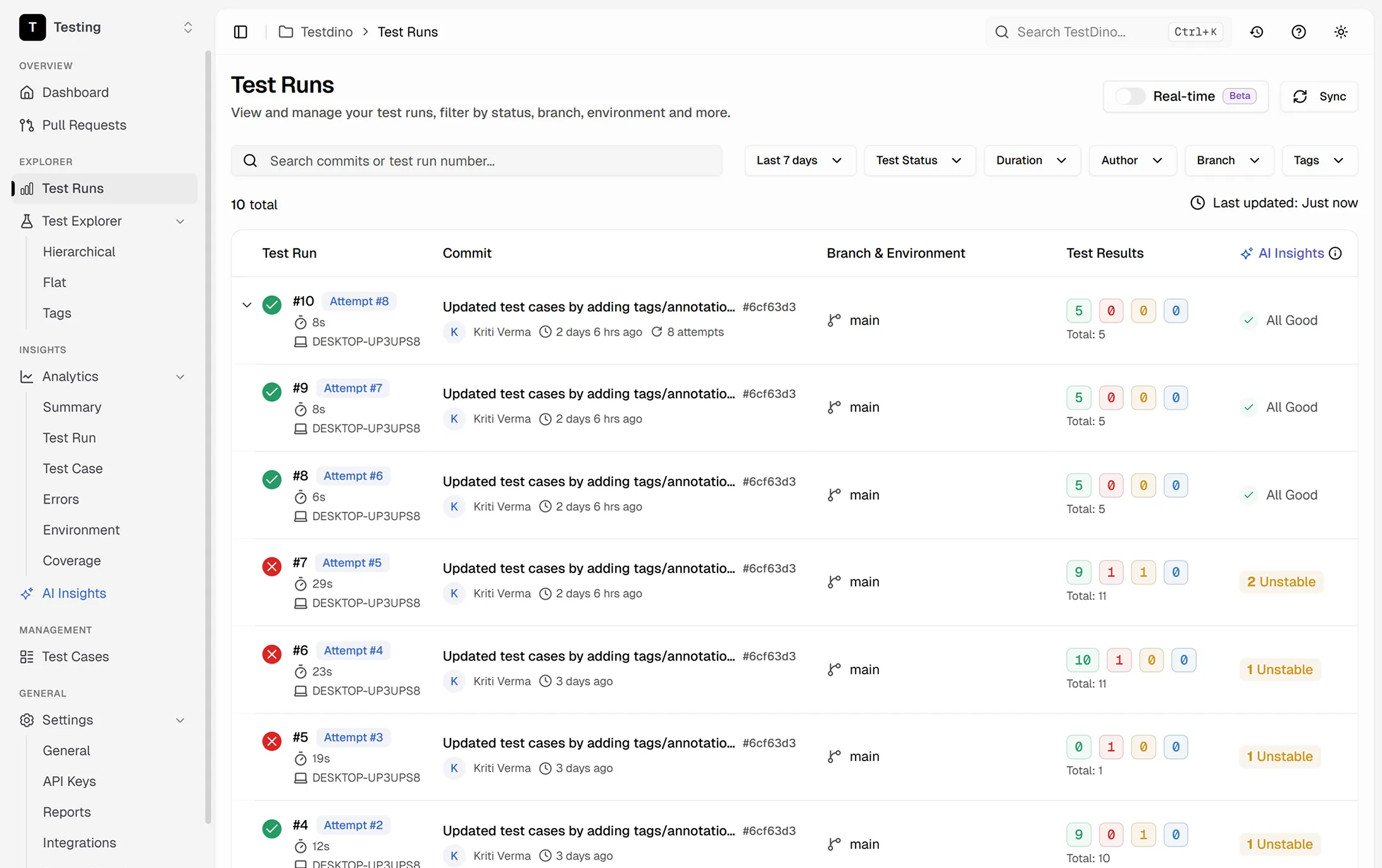
Two CLI commands power the workflow. tdpw cache stores failure metadata after a run and tdpw last-failed returns Playwright arguments for the retry. The workflow detects reruns using github.run_attempt and switches between full suite and failed-only automatically.

Rerun only what failed
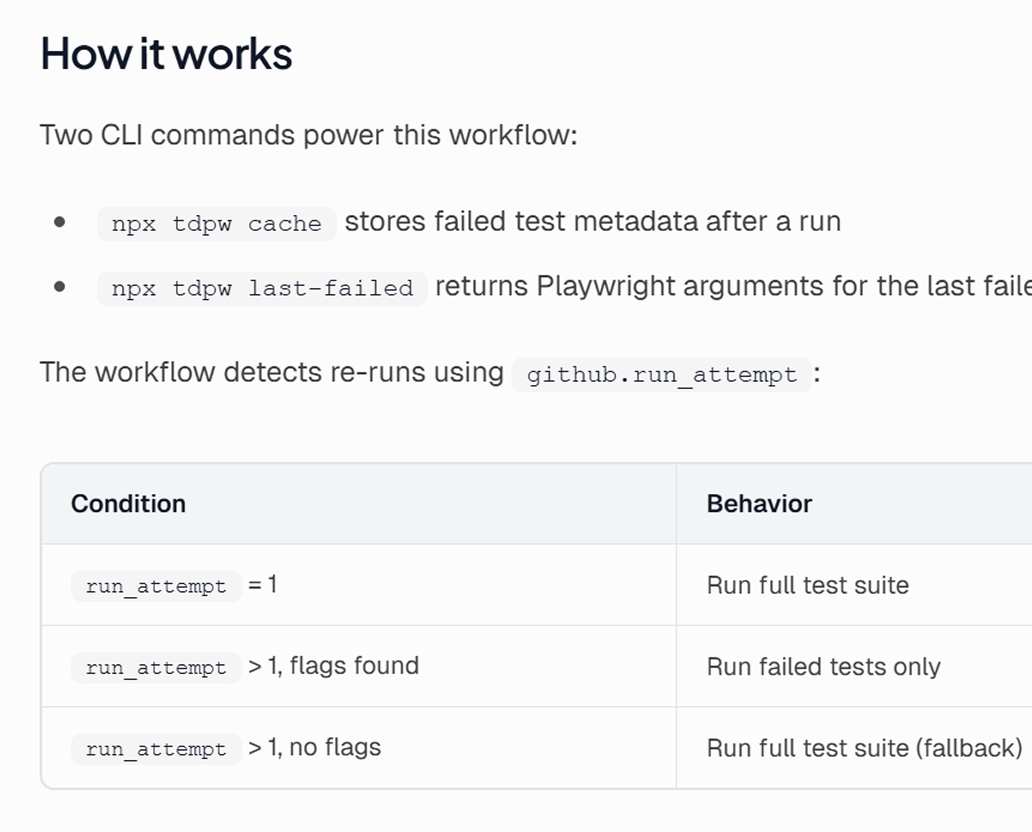
Add the rerun logic to your Playwright step. On retry, tdpw last-failed outputs grep flags for the failed tests. If flags exist, only those tests run. If not, the workflow falls back to the full suite.
Query failures via MCP
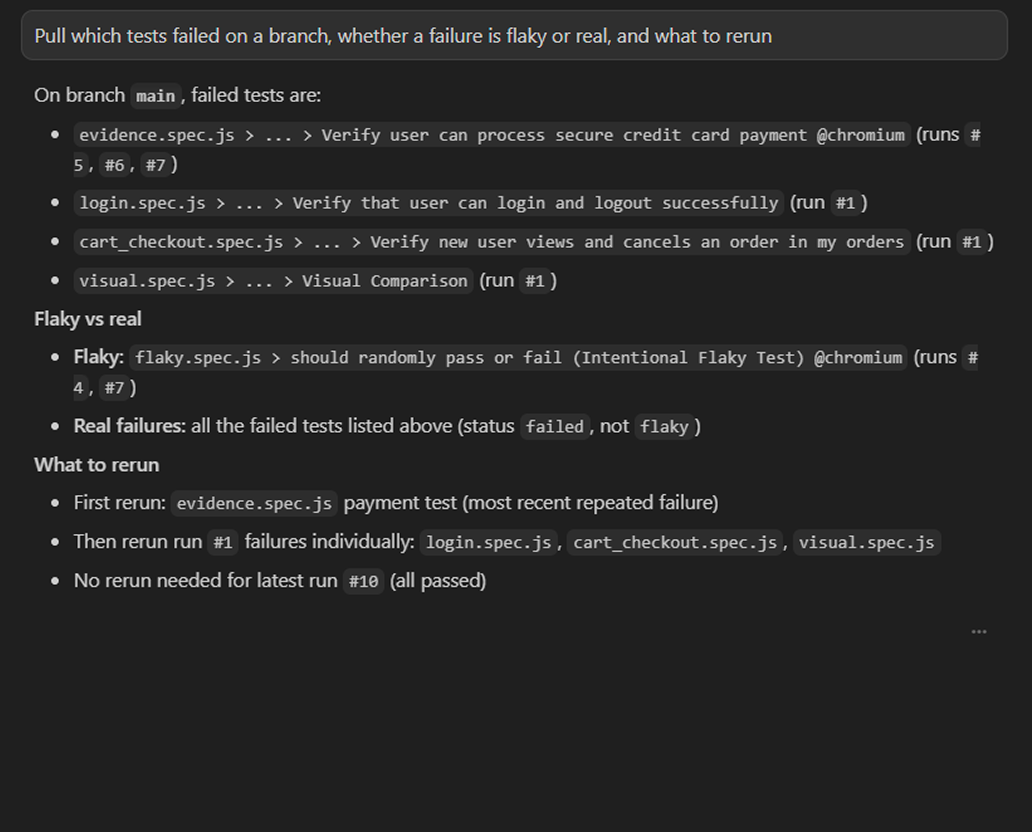
Connect the TestDino MCP server to your editor and pull which tests failed on a branch, whether a failure is flaky or real, and what to rerun, without opening the dashboard.
Teams love what we built
See why developers choose TestDino to ship faster and debug smarter
We were on the default Playwright reporter, and it was tedious to dig through; half a day gone just triaging failures. The TestDino MCP changed that for us. I now run through the failures in minutes instead of devoting half a day to it, and pulling the latest runs straight through the MCP sped up bug triage drastically. AI failure classification and Slack reports do the rest. It's saved us weeks.
To triage failures, down from half a day
Saved across the team

Migrating to TestDino from Currents was an easy decision. The features are stronger, the cost is lower, and the interface makes debugging far less painful. Flaky test detection and AI failure classification have simplified debugging and reduced our CI costs by cutting down reruns and noisy failures.
Reduction in CI costs
Less time triaging failures

Over 30 flaky tests and no structured way to track them, just CI artifacts and morning guesswork. TestDino's "Most Flaky Tests" feature broke this pattern. We can see failure trends now and pull up video recordings of exactly what went wrong. The TestDino MCP server is the magic piece on top, I ask my Claude agent about a failure and it pulls full context from TestDino without switching tabs. We went from 30-something flaky tests down to 3 or 4.
Fewer flaky test reruns
Faster failure triage

Precise failure tracking
across shards and branches
Per-shard failure filtering
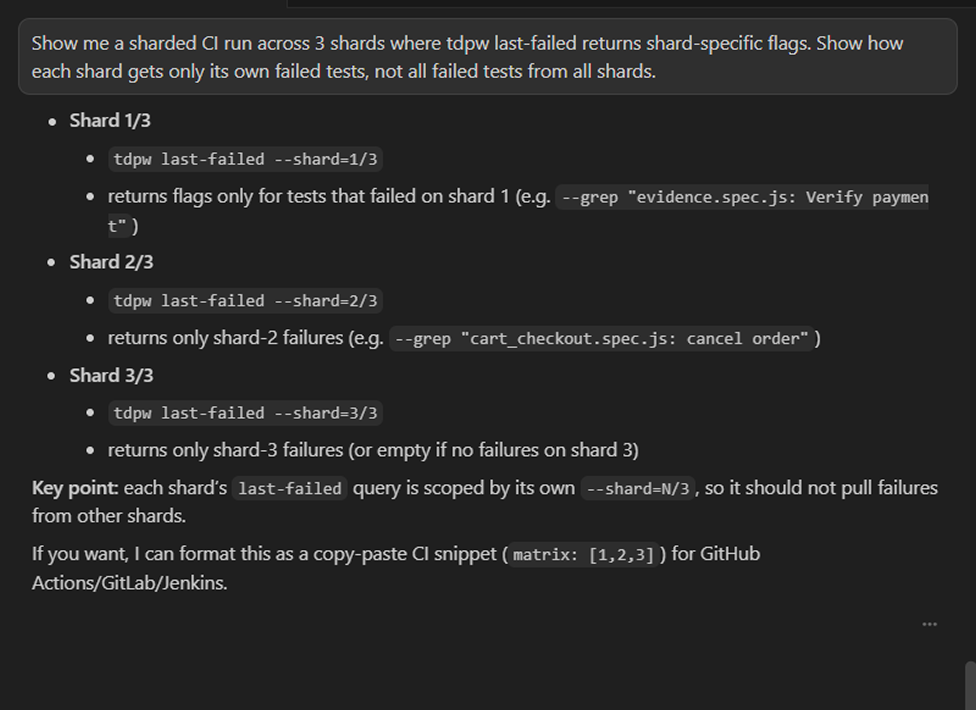
tdpw last-failed --shard=X/Y returns only the tests that failed in that specific shard, not every test in every failed shard.
GitHub Actions matrix compatible
Works with matrix strategies out of the box. Each shard reports independently and the CLI aggregates failures across all shards for your retry step.
Branch and commit aware
Every failure is tied to its branch and commit. Use --branch to override auto-detection or --commit for custom commit hashes.
Playwright-native grep output
tdpw last-failed outputs Playwright-formatted -g patterns you pipe directly into npx playwright test. No parsing, no test list files.
Automatic fallback to full suite
If the pipeline failed before tests ran, or no cached metadata exists, last-failed returns empty and your workflow falls back to the full suite.
Cross-runner cache persistence
tdpw cache stores metadata that survives fresh CI runners. Failure context is always available for the retry step regardless of how your CI is structured.
What you get with selective reruns
A 500-test suite takes an hour. A failed-only rerun takes 6 minutes. That adds up fast.
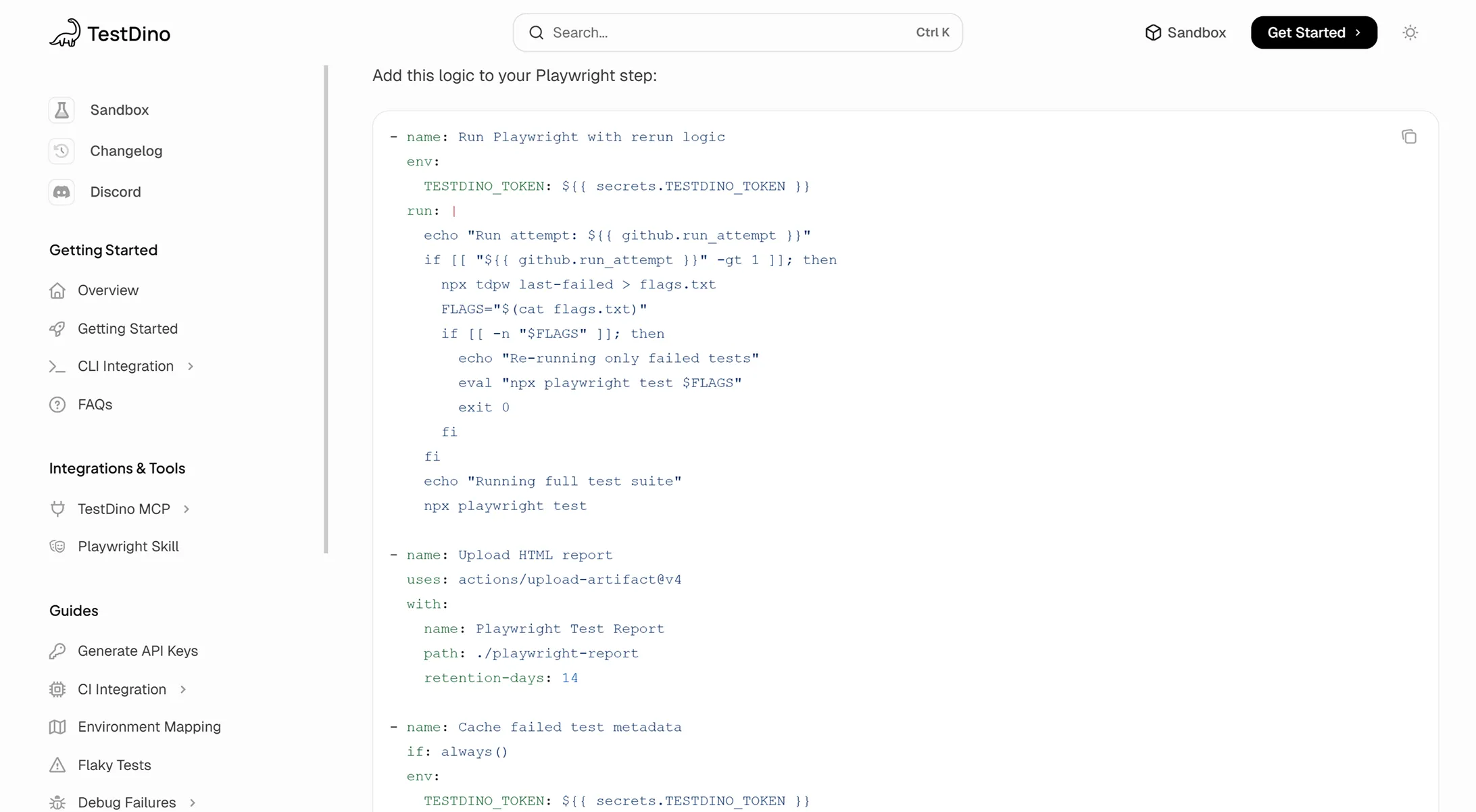
Retry workflow that fits into any CI pipeline
Add tdpw cache after your test step and tdpw last-failed in your retry condition. The CLI handles shard mapping, branch detection, and Playwright argument formatting. Your existing workflow stays the same.
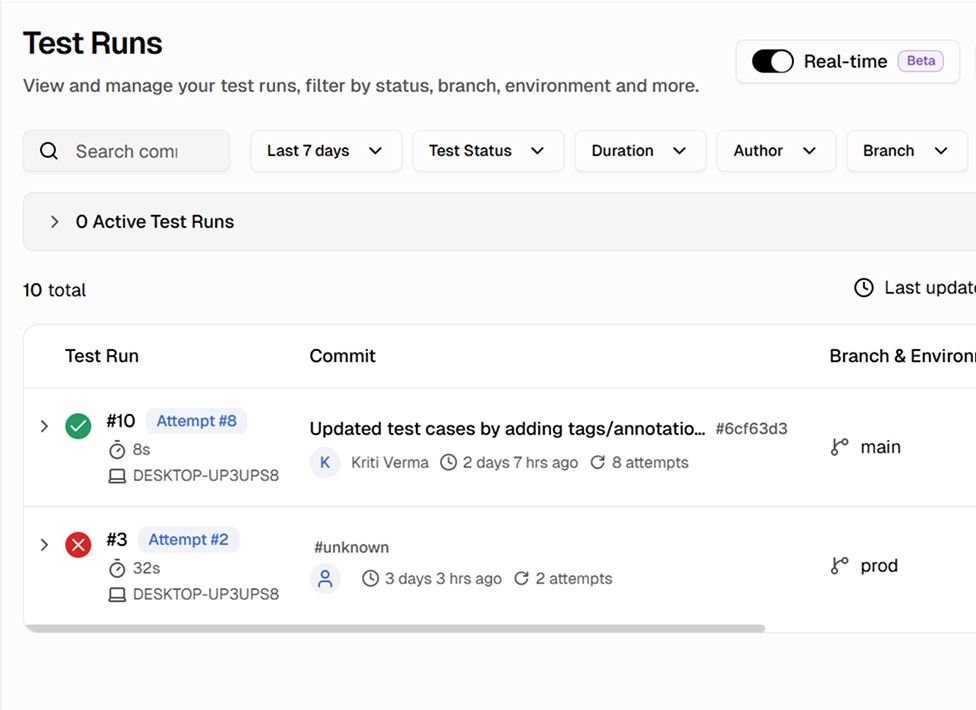
Full attempt history grouped by branch and commit
TestDino groups reruns by branch and commit and keeps the full attempt history together. See which tests failed on the first run, which passed on retry, and which kept failing across every attempt.
Works with Playwright 1.50+ native last-failed
Playwright added --last-failed in 1.50, but it only works within a single runner. TestDino adds cross-runner caching and workflow-level persistence so failure metadata survives fresh CI environments and works across shards.
Works with your favourite tools
Connect seamlessly with Jira, Slack, GitHub, Linear, Azure DevOps, Asana, and monday to keep your workflow smooth and your team aligned.
FAQs
The `tdpw cache` command stores failure metadata after each run, including shard information. When you call `tdpw last-failed --shard=X/Y`, it returns only the tests that failed in that specific shard, formatted as Playwright grep patterns.