Top Software Testing Trends for 2026
The 2026 Software testing trends that hold up: agentic QA, test intelligence, and AI code, backed by data over hype.

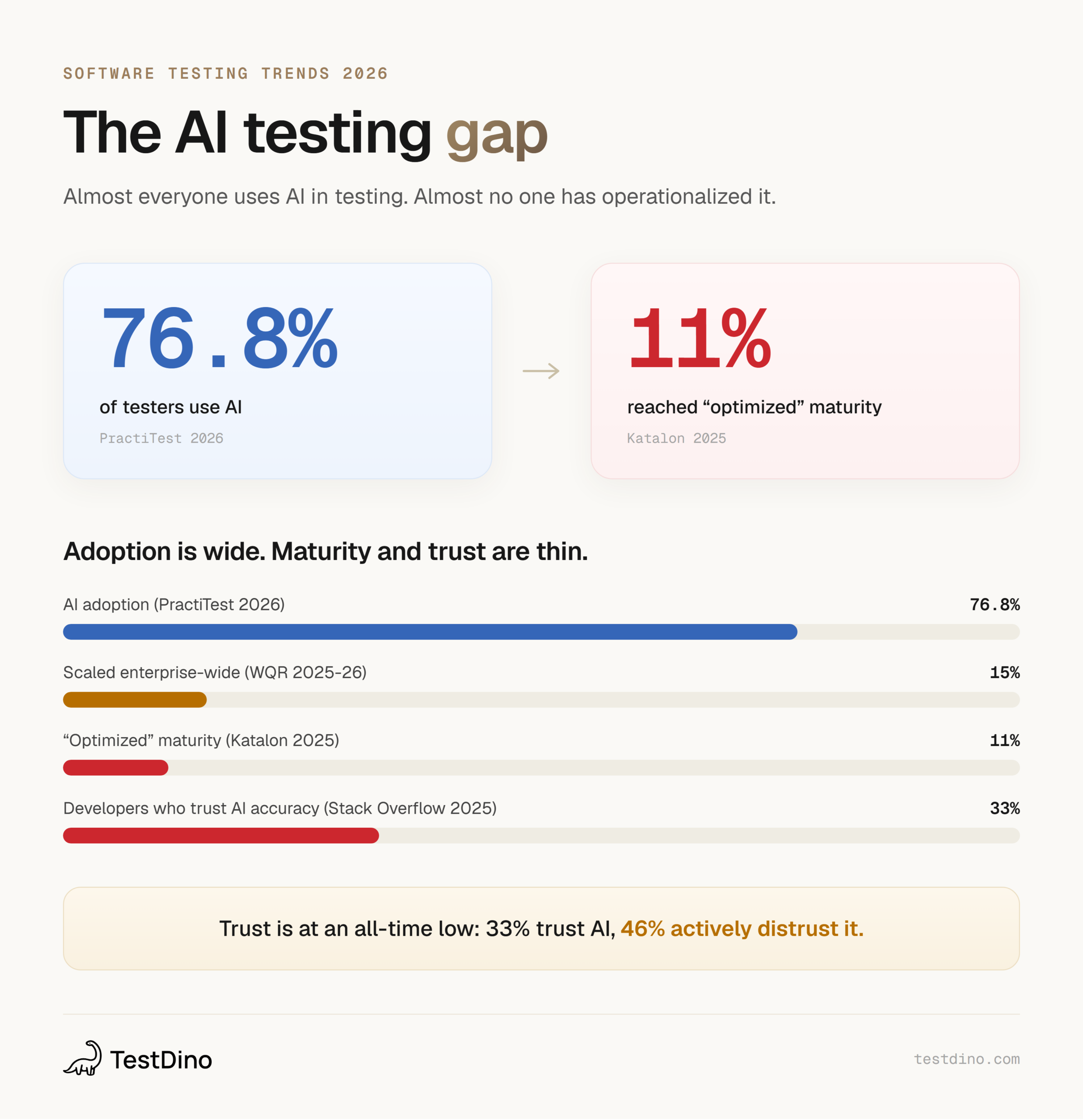
Every vendor blog says AI changed testing forever in 2026. The data tells a stranger story. 76.8% of testers now use AI, yet only 11% of teams have reached the top maturity stage, and developer trust in AI just hit an all-time low.
The tooling has evolved too. Playwright now out-downloads Cypress on npm, while Selenium still leads job postings. The framework wars cooled into a clear default.
Most Software testing trends 2026 lists read like a wishlist. Quantum testing. Self-healing everything. Robots replacing your team next quarter. But the trends worth your roadmap are the ones with evidence, and the gap between what surveys claim and what teams actually shipped.
This guide covers the 13 trends that hold up, each with a source, a contrarian counterpoint, and a clear call on whether to adopt it.

The 2026 testing landscape: Wide AI adoption, thin maturity
The most important number for software testing trends in 2026 is the gap between two stats.
76.8% of testers globally use AI, per the PractiTest 2026 State of Testing report (13th edition). Adoption hits 81.7% at enterprises and 70.6% at small businesses.
That sounds like a finished revolution. It isn't.
Only 11% of teams reached the "optimized" stage of QA maturity, per Katalon's 2025 State of Software Quality report. The World Quality Report 2025-26 agrees from another angle: 43% are still experimenting with Gen AI, 30% have limited use cases, and only 15% scaled it enterprise-wide.
So nearly everyone is using AI. Almost nobody has operationalized it.
This is the lens for the whole list. When a trend sounds finished, ask which stat measures adoption and which measures maturity. They are rarely the same number.
1. Agentic test automation moves beyond autocomplete
The defining shift of 2026 is from AI that completes a line of code to AI that runs a workflow.
An agentic testing workflow is one where an AI agent plans, generates, runs, and repairs tests across multiple steps, often driving a real browser, instead of returning a single suggestion. Playwright now ships planner, generator, and healer agents through the MCP, covered in TestDino's guide to Playwright test agents.
The tooling is even adding agent-specific guardrails. Playwright 1.60 (May 2026) shipped features aimed squarely at agent-driven testing:
| 1.60 feature | What it does | Why agents need it |
|---|---|---|
| ARIA snapshots with bounding boxes | Appends [box=x,y,w,h] to the accessibility tree | Machine-readable layout for agents, instead of screenshot guessing |
| test.abort() | Hard-stops a running test from a hook or fixture | A guardrail so an autonomous agent can't complete an unsafe action |
| errorContext | Surfaces the ARIA snapshot at the moment of failure | Gives the agent (and you) the DOM state behind a failed assertion |
These guardrails point to where agentic testing stands today. The research adds an important caveat.
Agent-generated tests do not reliably drive task success. A February 2026 study, Rethinking the Value of Agent-Generated Tests, analyzed 6 strong models on SWE-bench Verified, including Claude Opus 4.5 (74.4%) and Gemini 3 Pro (74.2%). Resolved and unresolved tasks showed similar test-writing frequencies. Suppressing test generation cut input tokens by 49% with only a 2.6% drop in success.
An agent writing its own tests looked productive while changing the outcome only marginally.
Honestly, agentic workflows are a genuine trend, while fully autonomous, unsupervised QA is still early. The four agent workflows mature at different speeds, broken down in AI agent testing: from hype to production.
What to do in 2026: Pilot agents on cheap-failure workflows (generation, exploration), keep a human gate on anything that touches your real suite.
2. How QA teams actually use AI in 2026
The way teams use AI in 2026 shows where it adds the most value today, and where human judgment still leads.
PractiTest 2026 breaks AI usage down by task. The pattern is consistent: adoption is highest for execution-layer work and lowest for judgment-layer work.
| AI is used for... | Share of testers | Layer |
|---|---|---|
| Test-case creation | 69.6% | Execution (extra hands) |
| Script maintenance | 59.6% | Execution (extra hands) |
| Test optimization | 35% (Katalon) | Mixed |
| Risk identification | 19.9% | Strategy (extra brains) |
Writing test code was rarely the bottleneck. Deciding what to test, which risks matter, and why a test should exist is the harder part, and it stays largely human for now. Generating the code is the first step, as TestDino's roundup of AI test generation tools notes. Producing tests that stay stable in CI is the job.
What to do in 2026: Let AI draft the boilerplate, then spend the saved time on coverage strategy and risk analysis, the judgment-layer work where adoption is still lowest.
3. Test intelligence: Analyzing failures, not just finding them
Here is the trend with the least hype and the most evidence: understanding failures matters more than generating tests.
Test intelligence is the practice of analyzing test results across runs to classify failures, detect flakiness, and surface root causes, instead of reading raw logs by hand. It treats test output as data, not a pass/fail light.
The research case is strong, and it comes from the structure of flakiness itself.
What the research shows:
- Flaky tests are systemic, not isolated. The EASE 2025 paper Systemic Flakiness ran 10,000 test-suite executions across 24 Java projects, found 810 flaky tests, and showed 75% of them belonged to clusters of co-occurring failures (mean cluster size 13.5). The dominant causes were intermittent networking and unstable external dependencies, shared across many tests at once.
- Test code alone can't classify flakiness. Can We Classify Flaky Tests Using Only Test Code? tested 3 LLMs across three prompting techniques; the best combination was only marginally better than random guessing. Its conclusion: you need runtime context, not just the code.
So "fix 200 flaky tests" is the wrong frame. "Fix the 4 root causes behind 150 of them" is the right one, which is what the tools in TestDino's flaky test detection roundup exist to do.
That is the whole argument for observability-rich test intelligence in one line. The model isn't the limit. The input is.
What to do in 2026: Stop counting flaky tests and start clustering them. More in TestDino's test intelligence platform overview.
4. Self-healing tests and their real-world limits
Self-healing tests are one of the most heavily marketed ideas of 2026, and one of the least supported by independent evidence.
Self-healing usually means a tool that, when a selector breaks, swaps in a new one and re-runs. It can help in narrow cases, but it is often positioned as full autonomy, and that gap is where teams run into trouble.
When we adversarially verified a 2026 paper claiming a self-healing agent framework significantly improved task success, the claim did not survive scrutiny. There is no strong, independent 2025-26 efficacy evidence that self-healing frameworks deliver measurable benefit at scale.
A deeper problem has surfaced: a test that silently rewrites its own selector can hide a real regression. If the button moved because someone broke the layout, "healing" the locator buries the bug you wanted to catch.
The well-established alternative is reliable, and it removes whole classes of flakiness without any AI, as TestDino's guide to reducing test maintenance lays out.
What actually reduces flakiness:
- Resilient locators that target stable attributes instead of brittle DOM paths.
- The Page Object Model to keep selectors in one place as the UI changes.
- Playwright's built-in auto-waiting, which removes most timing races before they start.
- Playwright's healer agent can suggest a repair, but a human still approves it.
What to do in 2026: fix your locator strategy before you buy a self-healing tool. Most "healing" is patching tests that were brittle by design.
5. Testing AI-generated code at scale
The most underrated trend of 2026 is that AI writes more code, faster, and someone has to test all of it.
The numbers are blunt. In Xray's own Sembi Software Quality Pulse Report (May 2026, nearly 4,000 respondents), 53% of code is now AI-generated or AI-assisted, and 61% report moderate to dramatic increases in testing demand driven by it.
So AI didn't reduce the testing workload. It raised it.
This is the counterintuitive part of the 2026 shift. The same tools that generate code faster also create more code to test. Faster output at lower trust means a larger QA queue, not a smaller one.
And trust is genuinely low. The Stack Overflow 2025 Developer Survey (49,000+ responses) found 84% of developers use or plan to use AI tools, up from 76% in 2024, but only 33% trust AI accuracy while 46% actively distrust it. Experienced developers are the most skeptical, because they have the longest history of debugging AI output.
What to do in 2026: Treat AI-generated code as untrusted input. Gate it with static analysis and review, and watch your suite for the flakiness it introduces.
6. Continuous quality: Shift-left and shift-right testing
Continuous quality reframes testing as a feedback loop that runs across the whole delivery cycle, not a single gate before release. In 2026, that loop has two ends, often discussed as shift-left and shift-right.
Shift-left means testing earlier, at design and commit time. Shift-right means testing in production through monitoring and observability. Together they describe continuous quality, a loop instead of a gate. The two directions split into distinct practices:
| Direction | Practices | Catches |
|---|---|---|
| Shift-left | Requirements review, API and contract tests, unit tests, security and accessibility in CI | Defects before they ship, when they're cheapest to fix |
| Shift-right | Production monitoring, synthetic checks, canary and chaos testing, real-user telemetry | What only appears under real traffic and real data |
Every roadmap has both. Almost no one has integrated them. The Sembi data is the reality check: only 26% of QA teams describe themselves as "mostly or fully integrated" with their DevOps pipelines. The other 74% bolt testing onto the side of delivery.
The teams that win this wired test results back into the pipeline, so a failure shows up on the pull request, not three Slack threads later.
What to do in 2026: Pick one direction and make it real. Get failure analysis onto the PR (shift-left) before chasing production observability (shift-right).
7. Cloud-based and cross-browser testing as the default
Running tests on your own machines is now the exception. In 2026, the grid lives in the cloud, and so does the device lab.
Cloud testing splits into two jobs: elastic execution and broad device coverage.
| Layer | What it gives you | The catch |
|---|---|---|
| Elastic execution | On-demand parallel runners, pay-per-use, no grid to maintain, faster pipelines via sharding | Cost creeps if you don't cap parallelism; cold-start latency |
| Cross-browser and device | Chrome, Firefox, Safari, Edge plus real iOS and Android, OS and resolution combinations, network throttling | Real devices cost more than emulators; flakiness rises with matrix size |
Playwright covers the browser matrix natively, and its sharding model is what makes cloud parallelism pay off. The trap is treating "we run on 30 browser-device combos" as coverage. A bigger matrix means more flaky surface area, which loops straight back to test intelligence (Trend 3).
What to do in 2026: Move execution to elastic cloud runners and shard aggressively, but cap the device matrix to the combinations your users actually run.
8. AI test data management: from masking to synthetic data
Test data quietly became the bottleneck nobody budgets for, and AI is reshaping how teams handle it.
The shift is from copying and masking production data to generating synthetic data on demand. The trade-offs are concrete:
| Aspect | Traditional (copy + mask production) | AI synthetic generation |
|---|---|---|
| Privacy risk | High, real PII in lower environments | Low, no real customer data |
| Setup time | Slow, manual masking rules | Fast, generated per run |
| Edge cases | Limited to what production contains | Can synthesize rare and boundary cases |
| Referential integrity | Hard to preserve across masked tables | Maintained by the generator |
| Compliance (GDPR, HIPAA) | Ongoing audit burden | Easier, synthetic by default |
The counterpoint: synthetic data is only as good as the model behind it, and a generator that misses a real-world distribution gives you confident tests against a fiction. Treat it as a tool to widen coverage, not as a reason to stop testing against realistic data. TestDino's roundup of test data management tools covers where each approach fits.
What to do in 2026: Use synthetic generation to kill PII risk and cover edge cases, and keep a sampled, realistic dataset for high-stakes flows.
9. Continuous performance testing across the release cycle
Performance testing stopped being the thing you run the week before launch. In 2026, it runs continuously, and the discipline splits by intent.
| Test type | Purpose | When to run | Key metric |
|---|---|---|---|
| Load | Behavior at expected traffic | Every release | Response time at target load |
| Stress | Breaking point beyond normal | Before major launches | Failure threshold |
| Spike | Sudden traffic surges | Before known events | Recovery time |
| Endurance | Stability over hours or days | Periodically | Memory leaks, degradation |
| Scalability | How adding resources helps | Capacity planning | Throughput per node |
Continuous performance testing only helps if someone reads the trend line. A graph of p95 latency that nobody reviews adds little. As with flaky tests, the value is in the analysis, not the run.
What to do in 2026: Wire a lightweight load check into CI for critical paths, and track the trend over releases instead of running one big test before launch.
10. Automated accessibility and visual testing in CI
Accessibility moved from "audit once a year" to "check on every pull request," and AI accelerated it.
The need is not subtle. WebAIM's 2025 analysis of the top million homepages found an average of 51 detectable WCAG errors per homepage. Automated scanning with axe-core wired into Playwright catches roughly 57% of issues by volume, as TestDino's Playwright accessibility testing guide documents.
That 57% is also the honest limit. Automation catches the machine-detectable half. Keyboard flow, screen-reader experience, and cognitive accessibility still need a human. The same caution applies to AI visual testing; vision models flag pixel changes well and judge intent poorly.
What to do in 2026: Make accessibility a CI gate to catch the automatable 57%, and keep a manual pass for the rest. "We run axe in CI" is not the same as "we are accessible."
11. API-first and contract testing for distributed systems
As architectures fragment into more services, and AI agents call more APIs, testing the contracts between them moved from nice-to-have to default.
API-first testing validates an API and its contract before the end-to-end scenario runs, catching integration breaks early instead of at the UI. The 2026 shift is consolidation: teams already running Playwright for UI now run API tests in the same framework, as TestDino's Playwright API testing guide shows, sharing auth state and one runner.
The counterpoint is cost. Contract testing adds upfront work, writing and maintaining the contracts, that many teams skip until an integration breaks in production. It pays off at scale and feels like overhead before then.
What to do in 2026: If you run microservices or your app calls AI APIs, contract-test the critical paths now. If you're a monolith with two integrations, this can wait.
12. Exploratory testing as the human complement to AI
Exploratory testing is easy to overlook because no tool sells it, yet it became more valuable as AI took over the scripted work.
When AI handles regression and boilerplate coverage, testers can focus on open-ended questions: unusual inputs, unspecified workflows, and edge cases no requirement described. Modern exploratory testing is structured rather than ad hoc:
- Charter the session: a clear mission, like "probe checkout under bad network."
- Time-box it: 60 to 90 focused minutes.
- Take notes as you go: what you tried, what surprised you.
- Log issues with repro steps.
- Debrief and convert the repeatable findings into automated tests.
This is the natural complement to Trend 2. AI generates the obvious tests; humans find the ones AI didn't know to write. The risk-identification gap (19.9%) is exactly the space exploratory testing fills.
What to do in 2026: Protect time for charter-based exploratory sessions, and feed what they find back into your automated suite.
13. Playwright, Selenium, and Cypress in 2026
Playwright's momentum is real. The "Selenium is dead" headline is not.
The adoption signal is clear across two independent measures.
The adoption signal:
- npm downloads: Playwright reaches 20 to 30 million weekly downloads versus Cypress at around 5 million, and surpassed Cypress in mid-2024 and kept widening the gap.
- Job postings: Playwright postings grew 3x in two years, per TestDino's Test Automation Jobs Report 2026.
- Selenium's installed base: Selenium still leads raw job postings, with 8,800+ roles in that same report.
Its 2026 status is covered in the data-driven is Selenium dead breakdown, which lands on "no, but Playwright wins new JavaScript and TypeScript projects."
One caution, because it spreads every year. Claims of a large "Playwright salary premium" over Selenium do not hold up against the primary survey data. We checked, and the specific 38% figure that circulates could not be verified. Choose Playwright for its architecture, compared in Playwright vs Selenium, not for a pay bump the data doesn't support.
What to do in 2026: Default to Playwright for new web projects, keep Selenium where it already works, and treat the unverified salary-premium claims with caution.
The 2026 decision framework: Adopt, pilot, or skip
Not every trend deserves your roadmap. Here is the call on each, with the evidence strength behind it.

| Trend | Verdict | Why |
|---|---|---|
| Test intelligence/failure analytics | 🟢 Adopt now | 75% of flaky tests are systemic clusters; the payoff is in root cause |
| AI-assisted test creation | 🟢 Adopt now | 70% already use it; works as a drafting tool with human review |
| Cloud + cross-browser execution | 🟡 Adopt now | Elastic runners and sharding cut pipeline time; cap the matrix |
| Accessibility in CI | 🟡 Adopt now | Catches 57% of issues automatically; cheap to wire in |
| Playwright for new web projects | 🟡 Adopt now | Leads downloads and new-project adoption; Selenium stays for legacy |
| Continuous quality (shift-left first) | 🟢 Pilot carefully | Only 26% are integrated; start with PR-level failure visibility |
| Agentic test workflows | 🟡 Pilot carefully | Real capability, unproven autonomy; keep a human gate |
| Testing AI-generated code | 🟢 Pilot carefully | Demand is rising 61%; build the review gate before scaling AI codegen |
| AI synthetic test data | 🟡 Pilot carefully | Kills PII risk; validate the generator against real distributions |
| Continuous performance testing | 🟡 Pilot carefully | Valuable only if someone watches the trend line |
| API-first / contract testing | 🟡 Pilot carefully | High value at scale, real upfront cost for small teams |
| Exploratory testing (structured) | 🟢 Keep doing | Fills the 19.9% risk-identification gap AI can't |
| Self-healing tests | 🔴 Wait and watch | No strong efficacy evidence; fix locators first |
| Quantum / XR / "autonomous QA" | 🔴 Skip for 2026 | Speculative; no production evidence this year |
A 12-week rollout plan for AI testing in 2026
Knowing what to adopt is half the work. Here is a sequence that doesn't overwhelm a team mid-year.
- Phase 1 (weeks 1 to 4): See your failures. Wire test intelligence into CI first. Cluster failures by root cause, so the rest of the work targets real problems instead of noise. This is the foundation every later phase reports into.
- Phase 2 (weeks 5 to 8): Move execution to the cloud. Shift runners to elastic cloud and shard the suite. Cap the browser-device matrix to what your analytics show users actually run. Pipeline time drops, and the failure data from Phase 1 tells you which combinations are worth keeping.
- Phase 3 (weeks 9 to 12): Add the cheap gates. Drop accessibility (axe in CI) and AI-assisted test creation into the existing pipeline. Both are low-effort once execution is fast and failures are visible. Keep a human review on every AI-drafted test.
- Phase 4 (ongoing): Standardize on Playwright for new work. New web projects start on Playwright. Migrate legacy Selenium only where the maintenance cost justifies it, not on principle.
The order matters: 1️⃣ Visibility, 2️⃣ speed, 3️⃣ coverage. Adding AI test generation before you can see your failures just generates more failures you can't read.
Beyond 2026: Where testing research is heading
The surveys describe today. The 2025-26 research papers hint at what's next, and they agree on a direction.
3 directions the research points to:
- Test generation gets hybrid, not fully autonomous. A systematic review of 115 studies, LLMs for Unit Test Generation, found prompt engineering dominates 89% of work but fault detection stays weak, with 87% of defects on average producing no valid test. Its roadmap points to autonomous agents paired with traditional tooling, not LLMs alone. Expect 2027 tools that wrap LLMs in coverage-guided and symbolic techniques.
- Flakiness detection moves to runtime context. The same research that showed test code alone can't classify flakiness (arXiv:2602.05465) points to the fix: feed models execution traces, network logs, and run history. The winning systems will be observability-rich, not prompt-clever.
- The expectations gap is the story to watch. A secondary study of 17 empirical works, Expectations vs Reality, found over 75% call AI-driven testing strategic while only 16% have adopted it. That gap closing, or not, is the real 2027 headline. The teams that operationalize the boring 11% will pull ahead of the ones still piloting demos.
None of this is quantum testing or self-healing autonomy. It's steady, evidence-backed progress toward systems that understand test results, with humans still steering.
Software testing trends 2026: Conclusion
The real software testing trends for 2026 aren't the flashy ones. They're the ones with evidence: AI everywhere but trusted nowhere, agents that assist more than they automate, and failure analytics doing more for reliability than any test generator.
The teams that win 2026 won't be the ones that adopted the most AI. They'll be the ones that knew which 11% of it was worth operationalizing.
Cluster your failures, gate your AI-generated code, and keep human judgment on the strategy. The hype resets next year. The data won't.
FAQs

Jashn Jain
Developer Advocate



